
Bigdata, Hadoop ecosystem, Semantic IoT등의 프로젝트를 진행중에 습득한 내용을 정리하는 곳입니다.
필요한 분을 위해서 공개하고 있습니다.
문의사항은 gooper@gooper.com로 메일을
보내주세요.
출처 : http://promaster.tistory.com/84
어찌되었든 DB만은 할수없는 일이다.
좋은(비싸기만 한것말고 적재적소의 데이터베이스) DB에 잘 설계된 데이터구조를 올려놓고 나면
잘만들어진 프로그램이 좋은 인터페이스 역할을 해야 좋은데이터가 만들어지는것이지.
DB혼자 잘나바야 데이터 넣기도 어렵고
개발혼자 잘나바야 데이터 꺼내서 활용하기도 어렵다.
개발과 DB는 어찌되었든 같이 조화가 되어야지 불화(?) 가 되어서는 안되는것 같다.
아무튼.
데이터 insert , select 를 위해서 hive를 이용해서 데이터 조작을 위한 테스트를 진행하려고 한다.
준비사항 :
1. hive-0.8.1-bin.tar.gz 안의 라이브러리들.
2. 개발툴 ( 나는 eclipse )
3. WAS 아무거나 ( 나는 tomcat - was라고 치자..... )
1. 설정 (관련 라이브러리 추가)
아래3가지 ( libfb , slf4j 2가지를 처음에 빼고 나머지만 라이브러리에 추가 했더니 에러도 잘 안나오고
실행은 안되고 알수가 없었다. 꼭 추가하길 )
hive-jdbc-버전.jar
hive-exec-버전.jar
hive-metastore-버전.jar
hive-service-버전.jar
hadoop-core-버전.jar
commons-logging-버전.jar
log4j-버전.jar
libfb버전.jar
slf4j-api-버전.jar
slf4j-log4j12-버전.jar
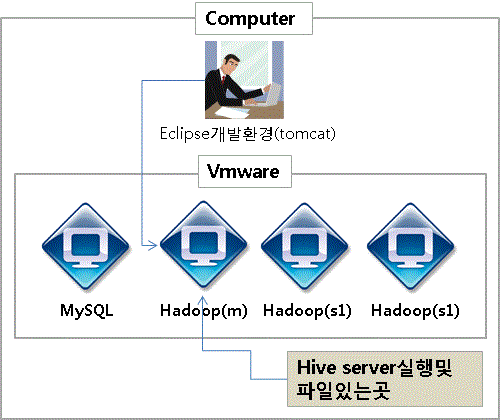
2. hive server 실행
Hive를 mysql에 연결한 작업까지 하고나서 이제 Hive 서비스를 띄운다.
(물론 HIVE_HOME 설정은 되어있는 상태이며 bin디렉토리까지 path로 잡아놓은 상태 이고 mysql 로 띄운상태이다.)
[hadoop@master1 ~]$hive --service hiveserver &
WARNING: org.apache.hadoop.metrics.jvm.EventCounter is deprecated. Please use org.apache.hadoop.log.metrics.EventCounter in all the log4j.properties files.
Hive history file=/home/hadoop/hive/log/tansactionhist/hive_job_log_hadoop_201208041919_1622721562.txt
아래는 그냥 로그파일에 찍히는 내용을 보고자띄움.
2. 테스트 (테스트는 https://cwiki.apache.org/Hive/hiveclient.html 에 있는 내용을 테스트함 )
아래는 해당 사이트에 있는 소스임 여기서 내서버와 관련된 설정만 바꾸도록 한다.
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveJdbcClient {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
/**
* @param args
* @throws SQLException
*/
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.exit(1);
}
Connection con = DriverManager.getConnection("jdbc:hive://192.168.0.141:10000/default", "", "");
Statement stmt = con.createStatement();
String tableName = "testHiveDriverTable";
stmt.executeQuery("drop table " + tableName);
ResultSet res = stmt.executeQuery("create table " + tableName + " (key int, value string)");
// show tables
String sql = "show tables '" + tableName + "'";
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
}
// describe table
sql = "describe " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "t" + res.getString(2));
}
// load data into table
// NOTE: filepath has to be local to the hive server
// NOTE: /tmp/a.txt is a ctrl-A separated file with two fields per line
String filepath = "/home/hadoop/test.txt"; // <---- 이걸 참고할것 아래에 내용 이어서.
sql = "load data local inpath '" + filepath + "' into table " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
// select * query
sql = "select * from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(String.valueOf(res.getInt(1)) + "t" + res.getString(2));
}
}
}
위의 파일경로와 파일명이 써있는부분의 파일생성은 hive 서버를 작동시킨 곳에다가 파일을 넣는다.
본인이 tomcat를 로컬에다가 띄웠다고 로컬에 넣는것이 아닌 hive서버 경로이다.
또한 그냥 단순히 apache.org에 있는 내용을 vi 로 작성했더니 인식을 못하더라 ;;;;; 예제 있는 쉘그대로 실행할것.
[hadoop@master1 ~]$echo -e '1x01foo' > /home/hadoop/test.txt
[hadoop@master1 ~]$echo -e '2x01bar' >> /home/hadoop/test.txt
아무튼 위처럼 파일을 생성하고나서 실행를 해보면 .
3. 결과
* 아래는 로그파일에 찍힌 내용
Hive history file=/home/hadoop/hive/log/tansactionhist/hive_job_log_hadoop_201208041919_859275775.txtOK
OK
OK
OK
Copying data from file:/home/hadoop/test.txt
Copying file: file:/home/hadoop/test.txt
Loading data to table default.testhivedrivertable
OK
OK
* 아래는 console 에 찍힌 내용
Running: show tables 'testHiveDriverTable'
testhivedrivertable
Running: describe testHiveDriverTable
key int
value string
Running: load data local inpath '/home/hadoop/test.txt' into table testHiveDriverTable
Running: select * from testHiveDriverTable
1 foo
2 bar
* hive로 들어가서 select 를 해본내용
[hadoop@master1 ~]$ hive
WARNING: org.apache.hadoop.metrics.jvm.EventCounter is deprecated. Please use org.apache.hadoop.log.metrics.EventCounter in all the log4j.properties files.
Logging initialized using configuration in file:/usr/local/hive/conf/hive-log4j.properties
Hive history file=/home/hadoop/hive/log/tansactionhist/hive_job_log_hadoop_201208042146_1805362014.txt
hive> select *From testHiveDriverTable;
OK
1 foo
2 bar
Time taken: 3.097 seconds
hive>
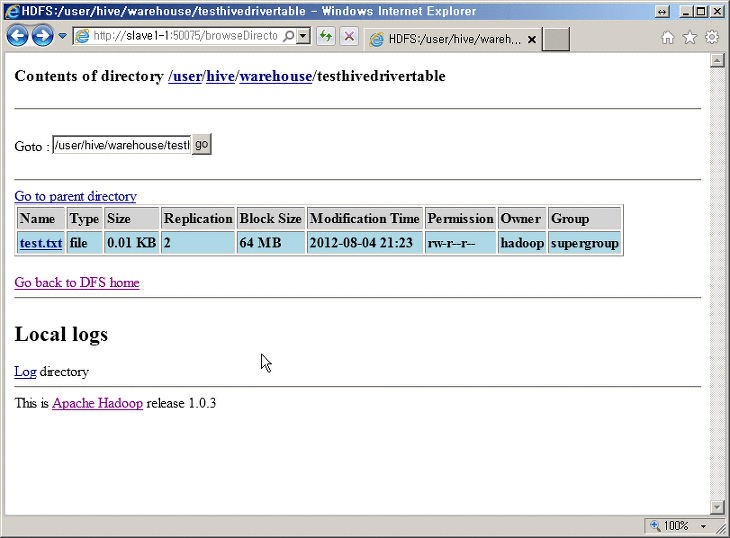
* Hadoop 관리자 모습 (test파일이 추가된모습 )
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 7 | hive에서 생성된 external table에서 hbase의 table에 값 insert하기 | 총관리자 | 2014.04.11 | 1748 |
| 6 | external partition table생성및 data확인 | 총관리자 | 2014.04.03 | 1072 |
| 5 | Hive Query Examples from test code (2 of 2) | 총관리자 | 2014.03.26 | 5005 |
| 4 | Hive Query Examples from test code (1 of 2) | 총관리자 | 2014.03.26 | 1050 |
| » |
Hive java connection 설정
| 구퍼 | 2013.04.01 | 2013 |
| 2 | Hive 사용법 및 쿼리 샘플코드 | 구퍼 | 2013.03.07 | 2991 |
| 1 |
Hive+mysql 설치 및 환경구축하기
| 구퍼 | 2013.03.07 | 2722 |