
Bigdata, Hadoop ecosystem, Semantic IoT등의 프로젝트를 진행중에 습득한 내용을 정리하는 곳입니다.
필요한 분을 위해서 공개하고 있습니다.
문의사항은 gooper@gooper.com로 메일을
보내주세요.
Hadoop wordcount 소스 작성
Hadoop (하둡) wordcount 예제 소스를 작성해보자.
본 포스팅에서는 이클립스에서 maven 프로젝트를 생성하여 작성하는 것으로
maven 설치가 안되어있다면 이전포스팅을 참고하기 바람.
메이븐 (maven) 설치 및 이클립스 연동하기 쉬운설명
하둡설치도 안되있다면..
메이븐으로 하둡 프로젝트 생성하기 |
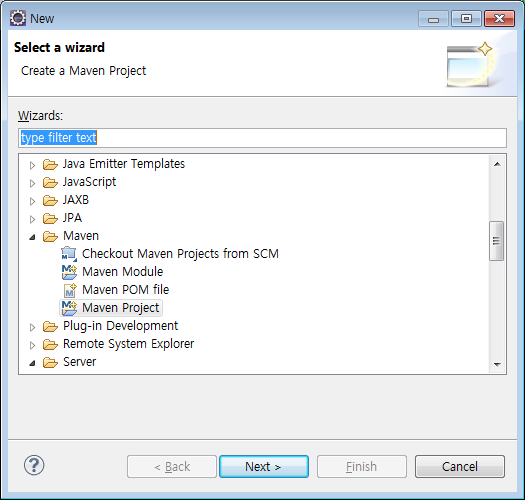
이클립스 상단메뉴에서
'File - New - Other' 를 클릭하여 프로젝트 생성창을 띄운 뒤
'Maven - Maven Project'를 선택한다.
Next 클릭~
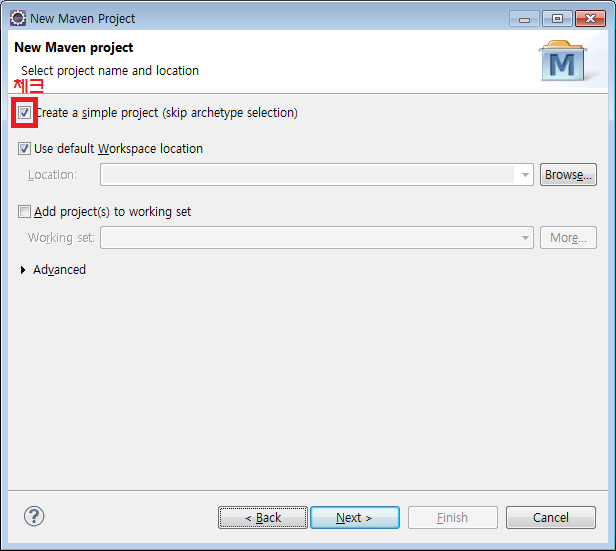
'Create a simple project' 에 체크를 하고 Next 버튼을 누른다.
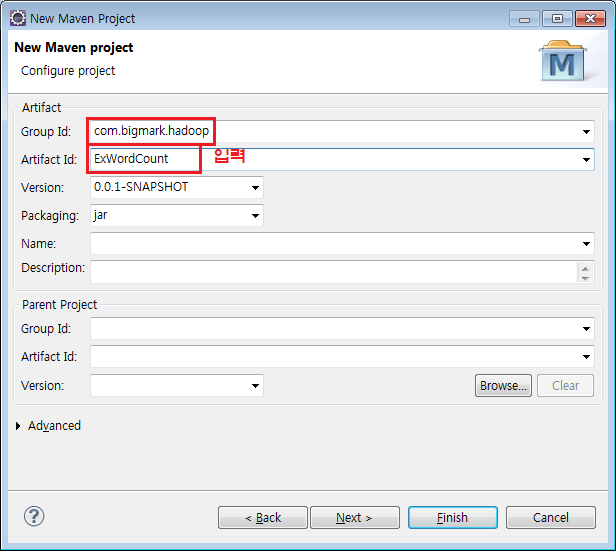
Group Id 와 Artifact Id 을 입력한다.
Group Id 는 패키지 네임, Artifact Id 는 프로젝트 네임 이라고 생각하면 된다.
Finish 를 누르면 프로젝트가 생성된다.
다음으로
하둡은 java 1.6 이상의 버전을 요구하기 때문에 JRE System Library 를 변경해 주어야 한다.
생성된 프로젝트에서 'JRE System Library' 를 우클릭 하고 'Properties' 를 클릭하면 아래와 같은 창이뜬다.
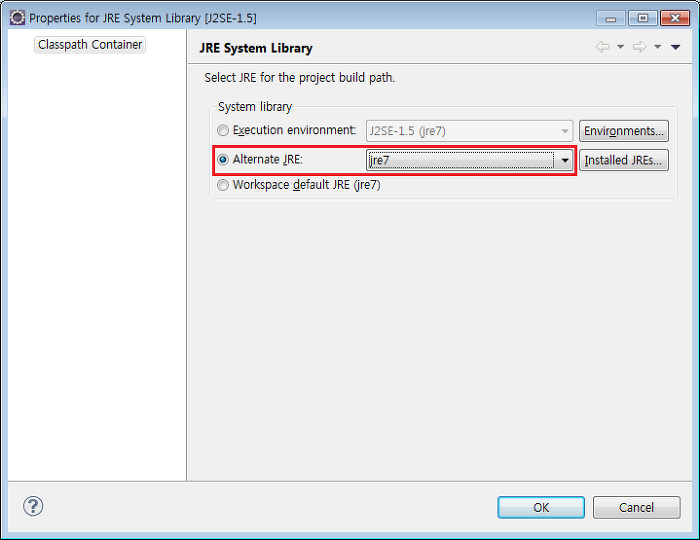
System library 에서 'Alternate JRE' 를 체크한 후 JDK 1.6 이상으로 설정한다.
다음으로 Maven Dependencies 에 라이브러리를 추가하여야 한다.
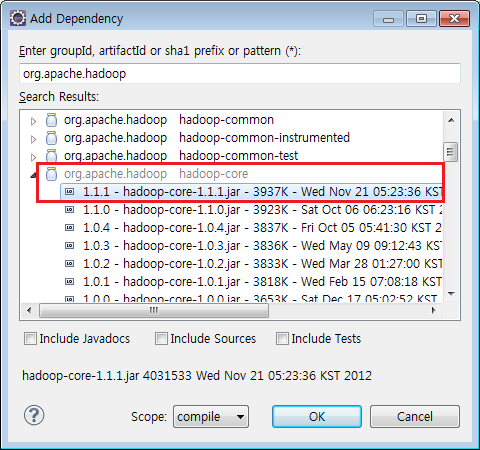
생성한 프로젝트를 우클릭하여 나타난 메뉴에서 'Maven - Add Dependency' 를 클릭한다.
Add Dependency 창이 나타나면 'org.apache.hadoop' 를 검색하여 hadoop-core 를 추가하여야 한다.
hadoop-core 버전은 본인이 설치한 hadoop의 버전으로 선택하면 된다.
wordcount 소스 작성하기 |
이제 wordcount 소스를 작성하도록 하겠다.
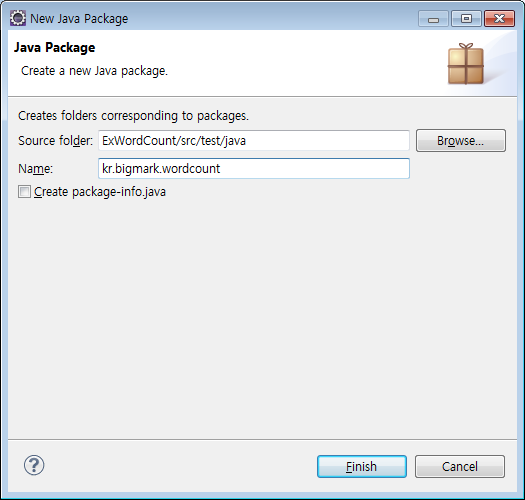
'src/test/java 우클릭 - New - Package' 를 차례로 클릭하여 패키지 생성창을 띄우고
Package 네임을 입력하여 (위 그림의 kr.bigmark.wordcount) 생성한다.
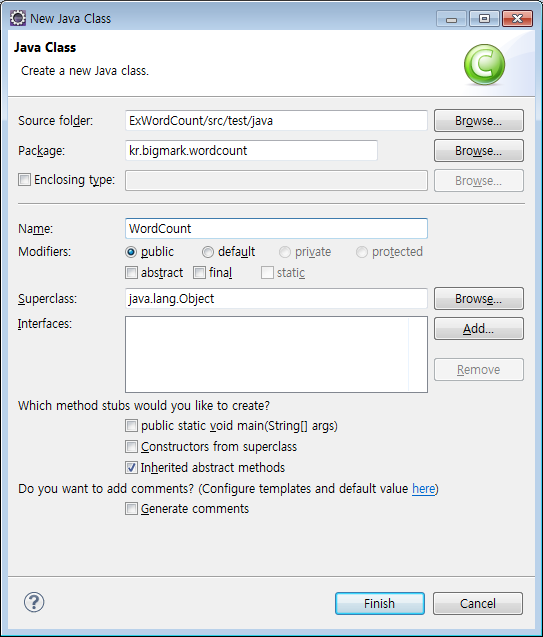
패키지가 생성되었으면
'생성된 패키지를 우클릭하고 New - Class' 를 선택하여 자바 클래스를 생성한다.
Class 생성 창에서 'Name : WordCount' 를 입력하고 Finish~
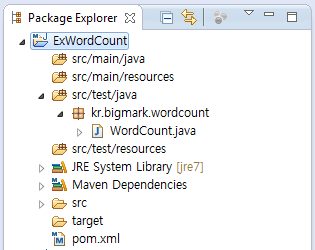
소스작성 전 모든 준비가 마무리되면 위 그림과 같은
구조로 나타날 것이다.
자 그럼 wordcount 소스를 코딩하자.
아래의 소스가 wordcount 소스이니 참고하고, package 네임은 본인 패키지에 맞게 변경할 것.
package kr.bigmark.wordcount; |
소스 작성이 완료 되면 jar 파일을 Export 하여 마무리 한다.
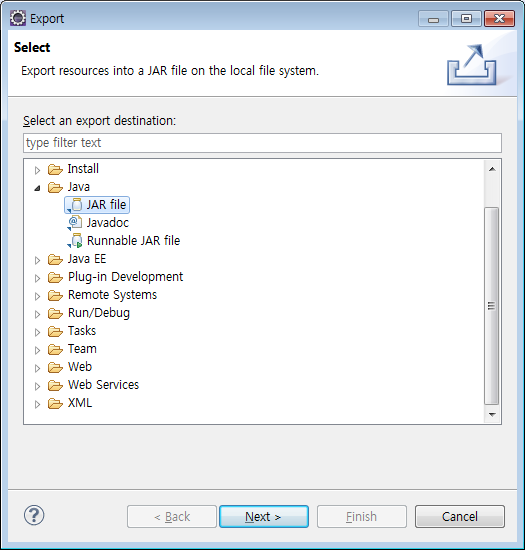
jar 파일 Export 하는 방법은
프로젝트 우클릭 - Export 를 누르고 Java - JAR file 를 선택한다.
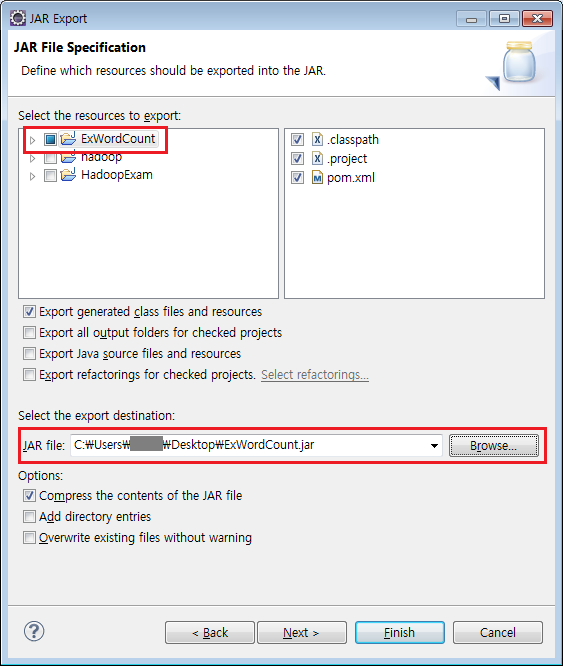
작성한 프로젝트인 'ExWordCount' 에 체크가 되어있는지 확인하고
Select the export destination 에서 'Browse' 버튼을 눌러 jar 파일을 생성할 경로를 입력한다.
Finish 버튼을 누르면 해당경로에 wordcount 의 jar 파일이 생성된 것을 확인 할 수 있을 것이다.
생성한 wordcount.jar 파일 실행방법은 다음 포스팅을 참조하시길~