
Bigdata, Hadoop ecosystem, Semantic IoT등의 프로젝트를 진행중에 습득한 내용을 정리하는 곳입니다.
필요한 분을 위해서 공개하고 있습니다.
문의사항은 gooper@gooper.com로 메일을
보내주세요.
Hadoop 설치 및 시작하기
Hadoop 의 구축 방법으로는
단독 작업 모드 (Stand-Alone Operation), 가상 분산 모드 (Pseudo-Distributed Operation), 완전 분산 모드 (Fully-Distributed Operation) 이렇게 3가지 방법이 있다.
본 포스팅에서는 가상 분산 모드(Pseudo-Distributed Operation)로 구축해 보도록 하겠다.
| 하둡 설치하기 |
아래의 아파치 하둡 페이지에서 다운로드를 받는다.
http://www.apache.org/dyn/closer.cgi/hadoop/common/
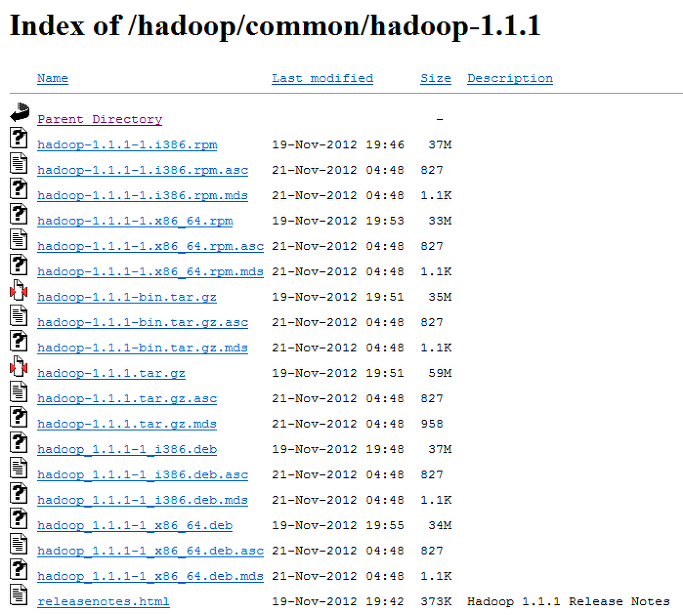
필자는 hadoop_1.1.1 버전을 받았으나, 다른 버전을 사용해도 상관없을 것이다.
tar.gz 로 끝나는 파일(hadoop-1.1.1.tar.gz)을 받으면 된다.
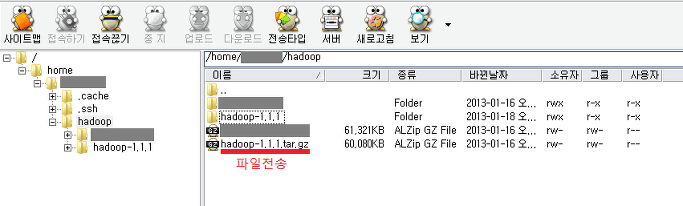
다운이 완료되었으면 알FTP를 통해 다운받은 파일을 전송한다.
전송이 완료되면
PuTTY 를 통해 원격접속하여 hadoop 설치를 진행하겠다.
서버에는 Ubuntu 12.04 버전이 설치되어있다.
그리고 자바는 필수적으로 설치되어 있어야 한다.(jdk1.6.x 권장)
알FTP로 전송한 hadoop-1.1.1.tar.gz가 있는 위치로 이동하여 tar파일의 압축을 푼다.
압축해제 명령어
tar -xvzf hadoop-1.1.1.tar.gz |
hadoop-1.1.1.tar.gz 의 압축을 푼 것으로 설치는 완료되었다.
하둡 설치경로를 환경 변수설정 해주어야 한다.
# cd
# vi .profile
export JAVA_HOME=/usr/lib/jvm/java-6-sun
export HODOOP_INSTALL=/usr/local/hadoop-1.1.1
export PATH=$PATH:$HADOOP_INSTALL/bin
환경 설정을 적용한다.
# source .profile
가상 분산 모드(Pseudo-Distributed Operation) 설정하기 |

압축해제한 폴더경로로 이동하여 파일들을 살펴보면 대략 이러한 파일들이 나올것이다.
input, output 폴더는 테스트과정에서 생성된것임
xml 문서작성하기
vi 편집기를 이용하여 다음 3개의 xml 을 아래와 같이 수정한다.
vi conf/core-site.xml vi conf/hdfs-site.xml vi conf/mapred-site.xml |
1. conf/core-site.xml
<configuration> |
2. conf/hdfs-site.xml
<configuration> |
3. conf/mapred-site.xml
<configuration> |
passphraseless ssh 설치하기
| $ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys |
| 실행하기 |
다음의 명령어를 차례로 입력한다.
$ mkdir input $ bin/hadoop namenode -format |
bin/start-all.sh 입력시 정상적으로 실행된다면 아래의 목록들이 확인될 것이다.
# jps
NameNode SecondaryNameNode JobTracker DataNode TaskTracker |
만약 bin/start-all.sh 입력시 'JAVA_HOME is not set' 이라는 에러가 뜬다면
$ vi conf/hadoop-env.sh 문서에서
export JAVA_HOME='자바경로' 를 입력한다.
export앞에 #은 주석처리이니 빼줄것
정상적으로 진행됬을 경우
cat output/* 입력시 결과가 출력된다.
![]()
1개의 일치하는 파일을 찾았다.
설치 과정에서의 troubleshooting
- start-all.sh 실행시 데몬 프로세스가 구동되지 않거나 JAVA_HOME 못찾는 경우
> vi conf/hadoop-env.sh 에 JAVA_HOME 환경 설정 부분 주석 제거하고 JAVA 설치 정보 수정해 줌
- java.io.IOException: Not a file: 오류 발생 시
> bin/hadoop fs -rmr input (input 삭제)
> bin/hadoop fs -put conf input (로컬의 conf경로에 있는 파일을 hadoop의 input에 다시적재)
- 구동 확인 방법
. http://localhost:50030/jobtracker.jsp
. http://localhost:50070/dfshealth.jsp