
In this post I am providing a 3 step process for performing UPSERT in hive on a large size table containing entire history.
Just for the audience not aware of UPSERT - It is a combination of UPDATE and INSERT. If on a table containing history data, we receive new data which needs to be inserted as well as some data which is an UPDATE to the existing data, then we have to perform an UPSERT operation to achieve this.
Prerequisite – The table containing history being very large in size should be partitioned, which is also a best practice for efficient data storage, when working with large data in hive.
Business scenario – Lets take a scenario of a website table containing website metrics as gathered from different browsers of visitors who visited the website. The site_view_hist table contains the clicks and page impressions counts from different browsers and the table is partitioned on hit_date(the date on which the visitor visited the website).
Just for the audience not aware of UPSERT - It is a combination of UPDATE and INSERT. If on a table containing history data, we receive new data which needs to be inserted as well as some data which is an UPDATE to the existing data, then we have to perform an UPSERT operation to achieve this.
Prerequisite – The table containing history being very large in size should be partitioned, which is also a best practice for efficient data storage, when working with large data in hive.
Business scenario – Lets take a scenario of a website table containing website metrics as gathered from different browsers of visitors who visited the website. The site_view_hist table contains the clicks and page impressions counts from different browsers and the table is partitioned on hit_date(the date on which the visitor visited the website).
Clicks – number of clicks(Eg on adds displayed) done by visitor on website page.
Impressions – number of times the website pages or different sections were viewed by the visitor.
Problem statement - If we receive correction in the number of clicks and impressions as recorded by browser, we need to update them in the history table and also insert any new records we received.
Impressions – number of times the website pages or different sections were viewed by the visitor.
Problem statement - If we receive correction in the number of clicks and impressions as recorded by browser, we need to update them in the history table and also insert any new records we received.
Lets dive into it:
In the history table we have browser_name and hit_date as a composite key which will remain constant and we receive updates in the values of clicks_count and impressions_count columns.
In the history table we have browser_name and hit_date as a composite key which will remain constant and we receive updates in the values of clicks_count and impressions_count columns.
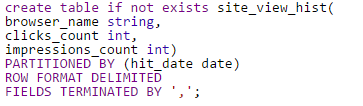
DDL of history table

Data:
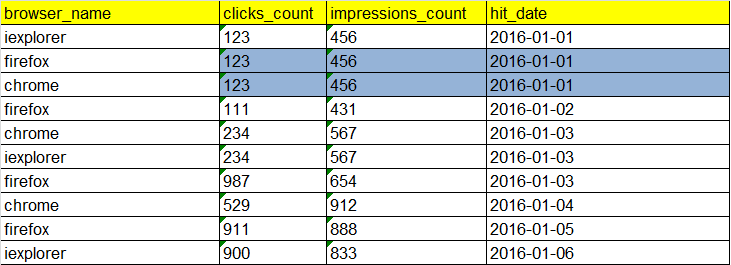
Now suppose we receive records for date 2016-01-01(marked in blue) for firefox and chrome browsers, with an updated value of clicks and impressions, and we also received a new record(iexplorer) for 2016-01-31. Let us store these new and updated records in the following raw table:

Now suppose we receive records for date 2016-01-01(marked in blue) for firefox and chrome browsers, with an updated value of clicks and impressions, and we also received a new record(iexplorer) for 2016-01-31. Let us store these new and updated records in the following raw table:
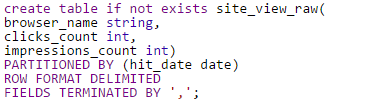
DDL of Raw table

Data

Now we need an UPSERT solution, which updates the records of site_view_hist table for hit_date 2016-01-01 and insert the new record for 2016-01-31.
SOLUTION (3 STEP):
To achieve this in an efficient way, we will use the following 3 step process:
Prep Step - We should first get those partitions from the history table which needs to be updated. So we create a temp table site_view_temp1 which contains the rows from history with hit_date equal to the hit_date of raw table.
This will bring us all the hit_date partitions from history table for which atleast one updated record exists in the raw table.
Note - Instead of table we can also create a view for efficient processing and saving storage space.

Data of site_view_temp1 table:
To achieve this in an efficient way, we will use the following 3 step process:
Prep Step - We should first get those partitions from the history table which needs to be updated. So we create a temp table site_view_temp1 which contains the rows from history with hit_date equal to the hit_date of raw table.
This will bring us all the hit_date partitions from history table for which atleast one updated record exists in the raw table.
Note - Instead of table we can also create a view for efficient processing and saving storage space.

Data of site_view_temp1 table:

Step 1 – From these fetched partitions we will separate the old unchanged rows. These are the rows in which there is no change in the clicks and impressions count. For this we will create a temp table site_view_temp2 as follows:

Data of site_view_temp2 table:

Step2 – Now we will insert into this new temp table, all the rows from the raw table. This step will bring in the updated rows as well as any new rows. And since site_view_temp2 already contained the old rows, so it will now have all the rows including new, updated, and unchanged old rows. Following query does this:

New Data of site_view_temp2 table

Step3 – Now simply insert overwriting the site_view_hist table with site_view_temp2 table, will provide us the required output rows including two updated rows for 2016-01-01 and one new inserted row for 2016-01-31.
Catch – Since the history table is partitioned on the hit_date, the respective partitions will only be overwritten as follows:

Final history table with updated and inserted rows:

Benefits of this approach:
- In the prep step itself since we are fetching just the partitions we have to update, so we are not scanning the whole history table. This makes our processing faster.
- In the final step as we are insert overwriting the history with the temp table, we are touching just the partition we want to update along with a new partition created for the new record.This gives a high performance gain, as I gained for my production process on a 6.7 TB history table with over 5 billion records. But since my 3 step process(included in one hive script) just touched few partitions of few thousand rows, the process completed in just minutes.