
Bigdata, Hadoop ecosystem, Semantic IoT등의 프로젝트를 진행중에 습득한 내용을 정리하는 곳입니다.
필요한 분을 위해서 공개하고 있습니다.
문의사항은 gooper@gooper.com로 메일을
보내주세요.
e 다운로드 및 설치
우선 하이브를 사용하려면 하둡이 반드시 설치되어 있어야한다.
설치되어있지 않다면..
아파치 하이브 다운로드 사이트에 접속하여 다운로드 받는다.
http://www.apache.org/dyn/closer.cgi/hive/
hive-0.10.0 버전이 불완전하다는 말을 주변에서 듣고 (확실치는 않음)
hive-0.9.0 버전 다운로드 함.
리눅스 (우분투) 하둡 설치폴더로 이동 후 압축해제 한다.
| # tar -xzvf hive-0.9.0-bin.tar.gz |
압축 푼 것으로 설치는 완료되었으며,
설정을 해주어야 한다.
hive 환경설정 |
먼저 환경변수 등록을 해준다.
하둡 path 를 설정했던 .profile 로 이동
![]()
등록 저장 후 source .profile 로 적용
Hive에서 사용할 HDFS 에 디렉토리 구성하기
hadoop fs -mkdir /tmp |
| hive 실행하기 |
hive 실행하려면 하둡이 실행되어 있어야 한다.
| $ $HADOOP_HOME/bin/start-all.sh |
hadoop 이 정상적으로 실행되면 다음 명령어로 hive를 실행한다.
$ $HIVE_HOME/bin/hive hive> |
hive가 정상 작동 하는지 확인
hive> show tables; |
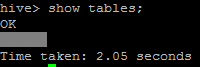
OK 가 떨어지면 제대로 설치 된것이다.
| mysql metastore 설정 |
mysql 을 metastore 로 설정하려면 당연히 mysql 이 설치되어 있어야한다.
mysql 서비스를 시작한다.
| # service mysql start |
루트 사용자의 암호를 설정한다.
mysql> grant all privileges on *.* to hiveid@localhost identified by 'hivepass' with grant option |
(mysql> grant all privileges on *.* to hive@localhost identified by '패스워드' with grant option;)
위 명령어의 hive 는 사용자 아이디이며, 패스워드는 사용자 패스워드이다.
다음으로 metastore로 사용할 db를 생성한다.
기존 db를 사용하려면 안해도 무방하다.
mysql> create database metastore_db; |
HIVE_HOME/conf 에 hive-site.xml 을 생성 및 작성한다.
<configuration> <property> <name>hive.metastore.local</name> <value>true</value> </property>
<name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/metastore_db?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property>
<name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>username to use against metastore database</description> </property>
<name>javax.jdo.option.ConnectionPassword</name> <value>패스워드</value> <description>password to use against metastore database</description> </property> </configuration> |
mysql connector 다운로드 http://www.mysql.com/downloads/connector/j/
다운로드한 mysql-connector-java-5.1.22.tar.gz 를 HIVE_HOME/lib/ 에 복사한다. (버전은 다를 수 있음)
mysql-connector-java-5.1.22.tar.gz 압축해제 하여 bin 폴더안에 있는 mysql-connector-java-5.1.22-bin.jar 파일만 넣으면 된다.
제대로 연동되었는지 다시한번 하이브 실행 확인한다.
위의 'hive 실행하기' 다시한번~
정상적으로 작동하면 mysql metastore 설정이 완료된것이다.
아래는 mysql없이 설정하는 방법임.
$ tar -xzvf hive-0.9.0.tar.gz |
$ ln -s ./hive-0.9.0 hive $ export HIVE_HOME=/usr/local/hduser/hive |
$ export PATH=$HIVE_HOME/bin:$PATH |
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp $ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse |
$vi $HOME/.bashrc --> 다음을 설정한다. #hive 실행을 위해 HADOOP_HOME, HADOOP_VERSION 설정한다. export HADOOP_HOME=/usr/local/hduser/hadoop export HADOOP_VERSION=0.20.205.0 export PATH=$PATH:$HADOOP_HOME/bin #hive 경로 설정 export HIVE_HOME=/usr/local/hduser/hive export PATH=$PATH:$HIVE_HOME |
#hive 라이브러리 CLASSPATH에 추가하는 부분. (기본 설정 부분.) for f in ${HIVE_LIB}/*.jar; do CLASSPATH=${CLASSPATH}:$f; done #hadoop library classpath setting (추가할 부분) for f in ${HADOOP_HOME}/lib/*.jar; do CLASSPATH=${CLASSPATH}:$f; done |
# Extra Java CLASSPATH elements. Optional. (기존 존재) export HADOOP_CLASSPATH=/usr/local/hadoop/hadoop-examples-0.20.205.0.jar #hive library classpath setting.(추가 사항) for f in ${HIVE_HOME}/lib/*.jar; do HADOOP_CLASSPATH=${HADOOP_CLASSPATH}:$f; done |
$ $HADOOP_HOME/bin/start-all.sh |
$ $HIVE_HOME/bin/hive hive> |
hive> CREATE TABLE pokes (foo INT, bar STRING); |
hive> SHOW TABLES '.*s'; |