사용을 해보기 전 가졌던 의문들은 다음과 같다. 의문에 대한 답은 정답이 아닐지도 모른다. 아직 코드 레벨에서 SparkR Core Code 까지는 까보고 확인해 보진 않았기 때문이다. 하지만, 실제 돌아가는 코드들을 하나 둘 만들어 수행해가며 실험을 해보니, 아래와 같은 유추가 가능하였다.
- Spark 는 Yarn 이나 Mesos 위에서 구동시 Spark 엔진을 모든 노드에 깔아줄 필요가 없다. R도 그럴가?
- SparkR은 R없이 동작되지 않는다. Local R과 Spark 엔진 사이에는 Layer 가 잘 나누어져 있는듯 하다. SparkR 모듈에서 R의 모든것을 처리하는 것이 아니라 인터페이스도 한다는 의미이다. 즉, bin 디렉토리에서 sparkR 을 수행하면, 로컬의 R이 반드시 있어야 그 위에서 무언가가 sparkR로서 완벽한 구동이 가능하다.
- R에서 사용하는 외부 Package 들은 모든 노드에 직접 설치 수행해 주어야 하나?
- 실험해 보니... 그렇다. 모든 노드에 설치해주지 않으면, 해당 모듈이 설치되지 않는 노드에서 계산 시 해당 노드에서만 에러가 난다.
- 외부 Package 설치는 일반적인 R의 그것과 동일하였다. SparkR 이 아닌 그냥 R 콘솔에서 install.package("패키지명") 하여 설치하면, SparkR 에서도 잘 인식 한다.
- 경로 참조는 어떤식으로 이루어 지나?
- 여러가지 메소드를 사용해보았는데, 동작 방식이 다소 차이가 있었다.
- 어떤 메소드는 해당 노드의 로컬경로를 찾는 것이 있다. (주로 R 고유 메소드 들..)
- 그리고, 어떤 메소드는 Hadoop 에서 해당 경로를 찾는 것도 있었다. (옵션 인자 를 확인해보진 않았지만, default 옵션이 그렇게 동작하는 것들이 있었다.)
- SparkR 이 제공하는 특화 메소드들은 몇몇 Hadoop 이 default 인것들이 보인다.
- 전통적인 R 스타일의 코드는 동작하지 않나? 예를 들어 R이 제공하는 data.frame 을 모두 SparkR 이 제공하는 dataframe(RDD Base) 로 일부 코드레벨로 치환해주어야만 동작하나?
- 답은 아니다 이다.
- 전통적인 R 스타일 코드도 동작하고, SparkR 스타일로 치환한 스타일 코드 또한 당연히 잘 동작한다.
- 단, 전자는 병렬처리가 안되는 것을 확인하였다. 후자는 병렬 처리가 이루어 진다.
- Production Level 의 실용적인 R코드를 SparkR 로 치환하는 대 진입장벽은 어느정도 인가?
- 계산 로직을 처음부터 만드는 경우이거나, Primitive 한 계산 로직 혹은 데이타 가공 처리 위주의 Legacy R 코드는 SparkR 스타일로 치환하기가 크게 어렵진 않다.
- 단, data.frame 이나 data.read 부분의 메소드 들을 SparkR 스타일로 변경해주는 약간의 작업이 필요하다. 해당 코드들은 그러나 대부분 Legacy 코드의 5% 미만인 경우가 대부분일 것이다.
- 외부 Package 를 그대로 사용하는 경우는 약간 제약이 따른다. 일부 그래프 패키지 등은 SparkR 스타일로 계산을 끝내고, 자료구조에 최종 결과 Dataframe 만을 남긴 이후, 해당 data 를 R스타일 자료로 옮기고 그대로 사용가능하다. (sparkR 의 dataframe 을 input 으로 받아주지 못하는 Package 가 대부분이므로...) 초기 계산 data가 매우 크다 할지라도, 계산이 끝난 데이타는 양이 작아질 수 있으므로, 이 시나리오는 그런데로 available 할 수 있다.
- 하지만, 외부 Package 로 마이닝 로직을 거대 Input 데이타에 데고 수행해야 하는 경우, SparkR 의 DataFrame 은 병렬성을 지원하지만, 해당 패키지가 해당 자료구조를 Input 으로 받지 못하여 Package 사용에 제약이 따른다. 이경우 현재까지는 아래와 같은 우회 해결책 외에는 해결 방법이 없어 보인다.
- 우선은 Spark ML 등에서 제공하는 다른 유사 알고리즘. 혹은 Mahout 등이 제공하는 외부 모듈을 사용하여 해당 연산 Job 을 분리 수행 시키는 방법이 있을 것이다. (널리 알려진 알고리즘들은 대부분 이 방법으로 수행이 가능할 것이다.)
- 하지만, R 에서만 존재하는 알고리즘을 꼭 써야 하는 경우는.... 어쩔 수 없이, 패키지를 그대로 사용하지 못하고, 해당 패키지의 Primitive 한 소스 코드를 열어서 자료구조를 SparkR 스타일로 치환해주는 작업이 필요하다. (패키지의 소스 난이도에 따라 available 한 방법이 아닐 수도 있다.)
아래는 우선 각 Compute Node 에 R 설치하는 과정이다.
우선 CentOS6 장비들과 CentOS7 장비들의 설치 과정이 다소 차이가 있었다.
- centos 6 에서 Install
- wget http://mirror.us.leaseweb.net/epel/6/x86_64/epel-release-6-8.noarch.rpm
- wget https://www.fedoraproject.org/static/0608B895.txt
- sudo mv 0608B895.txt /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6 <-폴더생성됨
- sudo rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
- rpm -qa gpg*
- sudo rpm -ivh epel-release-6-8.noarch.rpm
- sudo yum install -y npm
- sudo yum install -y R
- centos 7 에서 Install
- epel-release & npm 최신 버전 설치
- wget https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
- sudo rpm -ivh epel-release-latest-7.noarch.rpm
- sudo yum install -y npm
- 이후 R설치 시도
- 이 경우 몇가지 Dependency 에러가 나는 경우가 있음. 각각을 rpm 찾아서 수동 설치
- wget ftp://ftp.muug.mb.ca/mirror/centos/7.1.1503/os/x86_64/Packages/blas-devel-3.4.2-4.el7.x86_64.rpm
- sudo yum install -y blas (버전이 devel 과 일치해야 함. 일치안할때는 rpm찾아서 깔아주면 됨.)
- sudo yum install -y gcc-gfortran
- sudo rpm -ivh blas-devel-3.4.2-4.el7.x86_64.rpm
- wget ftp://mirror.switch.ch/pool/4/mirror/centos/7.1.1503/os/x86_64/Packages/lapack-devel-3.4.2-4.el7.x86_64.rpm
- sudo yum install -y lapack (버전이 devel 과 일치해야 함. 일치안할때는 rpm찾아서 깔아주면 됨.)
- sudo rpm -ivh lapack-devel-3.4.2-4.el7.x86_64.rpm
- http://rpm.pbone.net/index.php3/stat/4/idpl/26647268/dir/centos_7/com/texinfo-tex-5.1-4.el7.x86_64.rpm.html 요기에서 texinfo-tex 모듈 다운로드 하여 인스톨
- sudo yum install -y tex
- sudo yum install -y texinfo
- http://rpm.pbone.net/index.php3/stat/4/idpl/29077368/dir/centos_7/com/texlive-epsf-svn21461.2.7.4-32.el7.noarch.rpm.html 요기에서 tex(epsf) 모듈 다운로드 하여 인스톨
- sudo rpm -ivh texlive-epsf-svn21461.2.7.4-32.el7.noarch.rpm
- sudo rpm -ivh texinfo-tex-5.1-4.el7.x86_64.rpm
- Dependency 모듈 모두 설치 후 R설치 재 시도
- sudo yum install -y R
앞서 질문과 자답에서 언급한 것 처럼 SparkR 병렬 구동에 앞서 위와 같이 R 을 모든 Compute Node 에 설치 해주어야 한다.
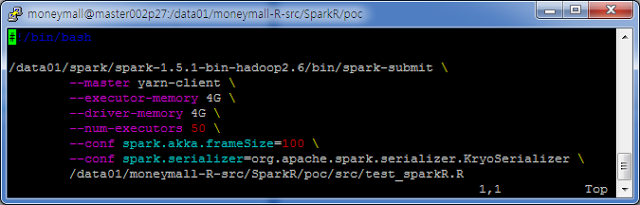
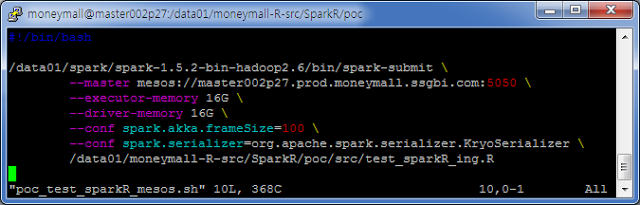
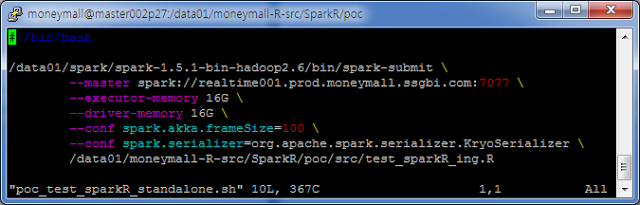
그리고 나면, 아래처럼 Spark Submit 으로 R 코드를 수행 할 수 있다.
- SparkR 실행 On Yarn
- SparkR 실행 On Mesos
- SparkR 실행 On StandAlone
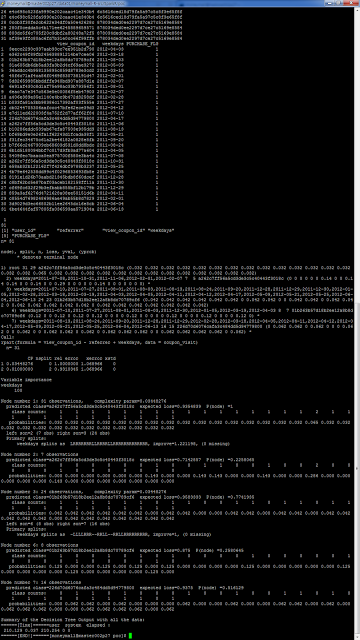
- 병렬 수행 후 결과 Output
- Legacy R 스타일 Code 수행
- 내부 Cat 한 로그 위주로 출력.
- Spark R 스타일 Code 수행
- 병렬 수행을 위한 Shuffle 로그도 함께 출력.
- R 콘솔
- SparkR 콘솔