Bigdata, Hadoop ecosystem, Semantic IoT등의 프로젝트를 진행중에 습득한 내용을 정리하는 곳입니다.
필요한 분을 위해서 공개하고 있습니다.
문의사항은 gooper@gooper.com로 메일을
보내주세요.
*문제가 있는 노드를 제거하는 경우 HDFS노드및 YARN노드를 동시에 제거해야한다.
(9대로 구성된 클러스터에서 4대(gsda5~9)를 해제하는 경우)
hdfs-site.xml에서 지정하는 dfs.hosts.exclude와 yarn-site.mxl에 지정되는 yarn.resourcemanager.nodes.exclude-path에 지정되는 노드는 slaves에 지정되는 노드와 다르게 네임노드와 리소스 매니저가 워커 노드의 접속 허용 여부를 결정할 때 사용된다. slaves파일은 클러스터 재시작과 같이 하둡의 제어 스크립트가 클러스터 전역에 걸치 작업을 수행하는데 사용된다. 하둡데몬은 slaves파일을 절대 사용하지 않는다.
1. nodes.include에 해제하지 않을 노드를 기록한다.(호스트명 또는 ip)
vi nodes.include
gsda1
gsda2
gsda3
gsda4
2. nodes.exclude에 해제할 노드를 기록한다.(호스트명 또는 ip)
vi nodes.exclude
gsda5
gsda6
gsda7
gsda8
gsda9
3. hdfs-site.xml파일에 포함/제외할 노드 목록이 있는 파일의 경로를 추가한다
<property>
<name>dfs.host</name>
<value>$HOME/hadoop/etc/hadoop/nodes.include</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>$HOME/hadoop/etc/hadoop/nodes.exclude</value>
</property>
4. yarn-site.xml파일에 포함/제외할 노드 목록이 있는 파일의 경로를 추가한다.
<property>
<name>yarn.resourcemanager.nodes.include-path</name>
<value>$HOME/hadoop/etc/hadoop/nodes.include</value>
</property>
<property>
<name>yarn.resourcemanager.nodes.exclude-path</name>
<value>$HOME/hadoop/etc/hadoop/nodes.exclude</value>
</property>
4-1. 각 노드에 반영해준다.(실제는 namenode가 기동되고 있는 노드에만 복사해도됨)
scp -P 10022 yarn-site.xml root@gsda2:$HOME/hadoop/etc/hadoop
scp -P 10022 hdfs-site.xml root@gsda2:$HOME/hadoop/etc/hadoop
scp -P 10022 nodes.include root@gsda2:$HOME/hadoop/etc/hadoop
scp -P 10022 nodex.exclude root@gsda2:$HOME/hadoop/etc/hadoop
*참고: yarn-site.xml과 hdfs-site.xml만 각 노드에 복사하고 exclude파일은./sbin/distribute-exclude.sh를 이용하여 namenode에 복사할 수 도 있다(https://www.gooper.com/ss/index.php?mid=bigdata&category=2789&document_srl=3565)
5. 변경된 노드정보를 네임노드및 리소스매니져에 반영하기 위해서 다음을 수행한다.
./bin/hdfs dfsadmin -refreshNodes
./bin/yarn rmadmin -refreshNodes
6. 해제 상태 확인
가. hdfs dfsadmin -report를 이용
- Decommission Status : 진행중 => Decommission in progress, 완료상태 => Decommissioned
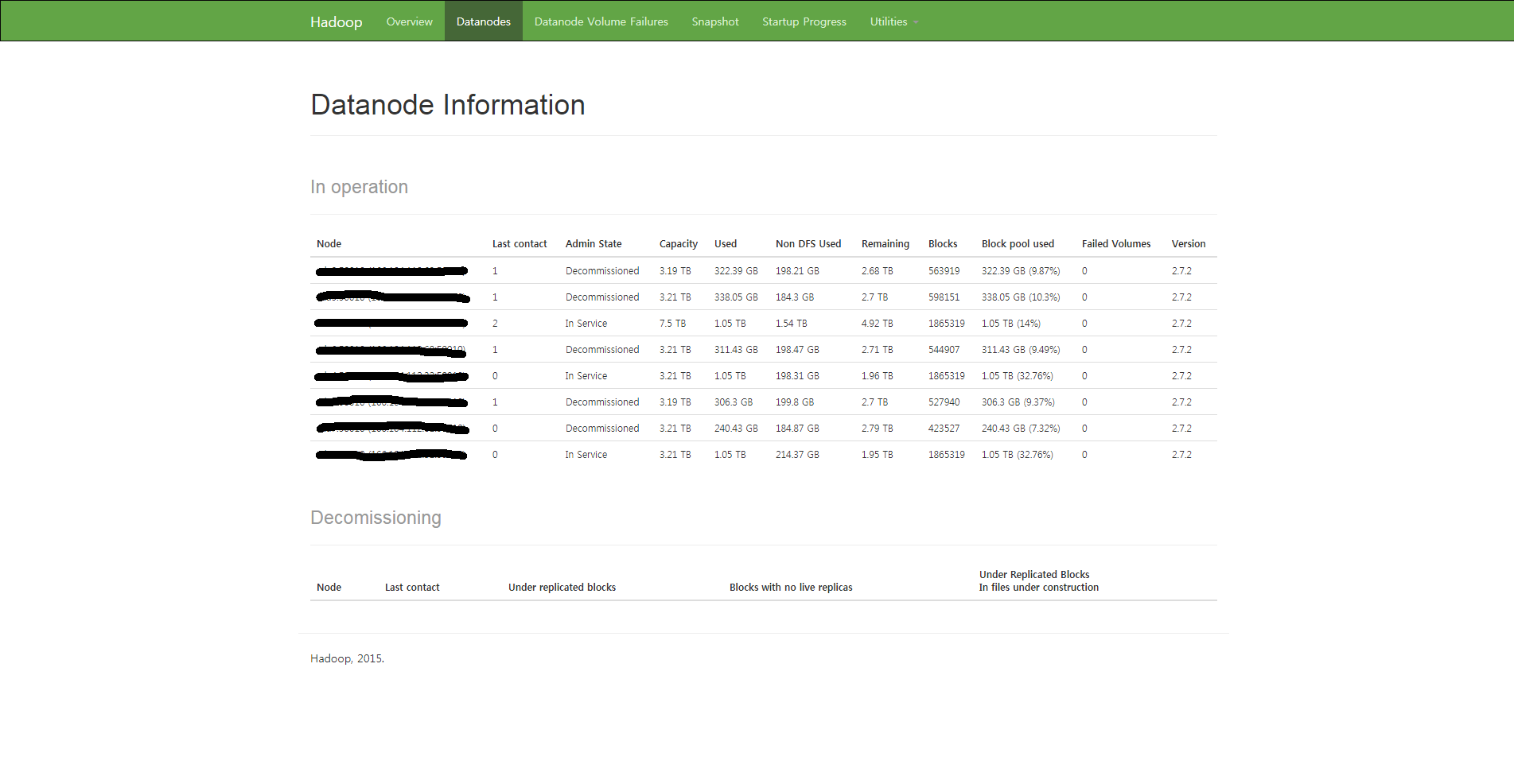
나. gsda1:50070에 접근하여 확인한다.
7. 퇴역노드를 중단시킨다.(웹UI에 접속해서 퇴역시킬 데이터노드의 관리상태가 Decommissioned가되면 블록의 복제가 완료된 것이다.)
-bash-4.1# ./hadoop-daemon.sh stop datanode
-bash-4.1# ./yarn-daemon.sh stop nodemanager(필요시)
(nodemanager는 ./bin/yarn rmadmin -refreshNodes를 실행하면 즉시 decommission되는거 같음)
8. include파일의 내용을 지우고(#으로 주석처리 가능함) 다음 명령어를 수행한다.
./bin/hdfs dfsadmin -refreshNodes
./bin/yarn rmadmin -refreshNodes
-> Datanode Information화면에서 Dead,Decommissioned가 표시되며 Decommissioned노드가 Dead상태로 바뀌지 않으면 어느정도 대기후 반복해서 실행한다.
(datanode 데몬이 살아 있으면 Dead상태로 바뀌지 않으므로 반드시 7번작업을 통해서 datanode데몬을 죽이고 실행해야함)
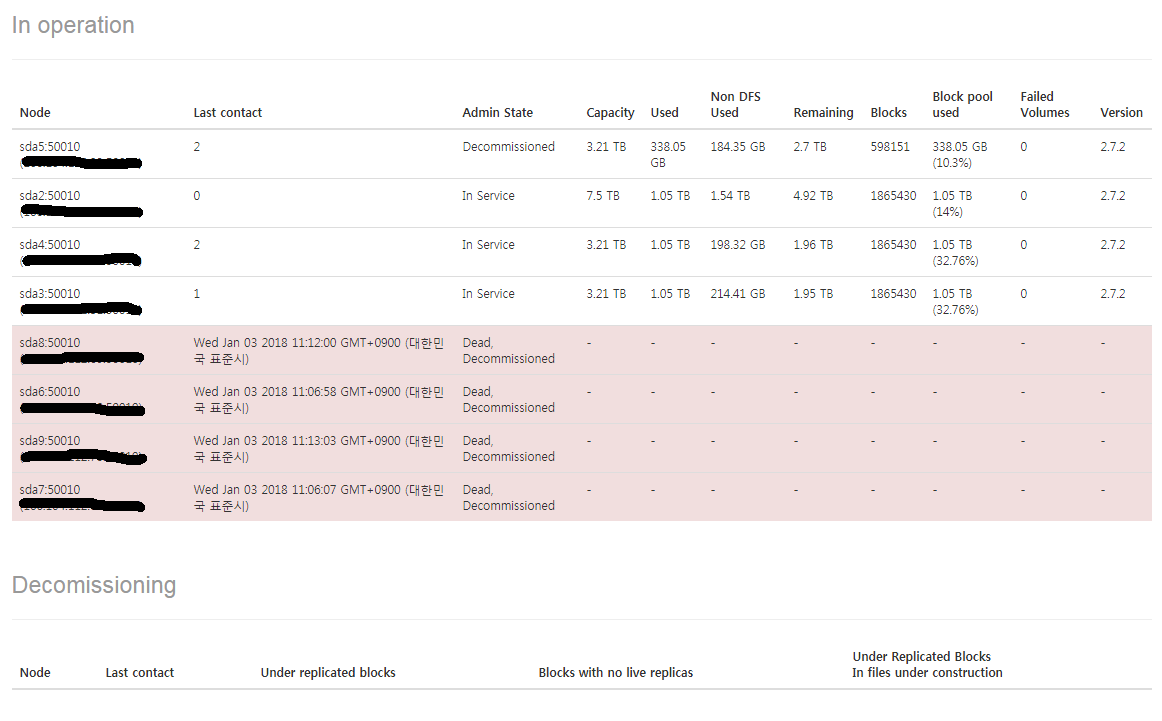
9. slaves파일에서 해당 노드를 삭제한다.
*참고 : 퇴역이 진행중에도 MR등의 작업은 정상적으로 진행됨