
Cloudera CDH/CDP 및 Hadoop EcoSystem, Semantic IoT등의 개발/운영 기술을 정리합니다. gooper@gooper.com로 문의 주세요.
/etc/logrotate.d 을 이용한 catalina.out 나누기
Apache Tomcat의 로그파일인 catalina.out은 기본적으로 한개의 파일에 로그가 쌓이게 됩니다.
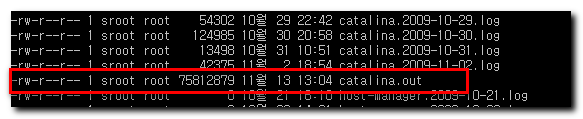
Tomcat을 재시작 하지 않는 이상 계속적으로 쌓이는 듯합니다. 벌써 용량이 후덜덜하네요.
이 파일을 다시는 볼일이 없다면 상관이 없지만...
열어 보려고 한다면... 시간 꽤 걸리듯합니다.
catalina.out의 만행을 그냥 두고 못 본척하신다면... 나중에 눈물 흘릴 수도 있습니다. :")
저도 모니터링 중에 문제가 생겨서 확인하려고 catalina.out 파일을 열어봤더니...
시간이 좀 걸리더군요...
그래서 catalina.out을 나누는 방법을 검색해봤습니다.
로그 파일을 rotate하는 방법에는 보통 4가지가 있습니다.
2. cronolog
3. logrotate
4. shell script
이번 포스트에서는 logrotate에 대하여 알아보겠습니다. 가장 사용하기 쉽고 제가 원하는 동작을 하더군요. :")
Apache Tomcat 로그 순환 설정 : http://koov.net/blog/?/tag/rotate
위 블로그 가시면 간단히 catalina.out 로그 파일을 자동으로 나누게 설정하는
방법이 있습니다.
$ cat > tomcat
/var/local/tomcat/logs/catalina.out {
copytruncate
daily
rotate 30
missingok
notifempty
}
$ logrotate -f /etc/logrotate.d/tomcat
실행 후 화면,

위 이미지와 같이 catalina.out.1 이라는 파일이 생성되는군요. 흠... 그럼 1, 2, 3 이런식으로 쌓일텐데 관리자의 입장에서는 좀 불편할 수도.... Buuuuuuuuuuut!!!!!
dateext 라는 옵션이 있군요!!!
$ cat > tomcat
/var/local/tomcat/logs/catalina.out {
copytruncate
daily
rotate 30
missingok
notifempty
dateext
}
$ logrotate -f /etc/logrotate.d/tomcat

알아두셔야 할 점은 copytruncate 옵션은 반드시 써야 한다고 합니다.
따라서 원래 로그를 다른이름으로 저장하고 새로운 catalina.out을 생성한다해도 실제 로그 스트림은 다른이름으로 지정된 원래 로그쪽으로 계속해서 쌓이게 됩니다.
이걸 방지하기 위해 현재 로그내용을 복사하여 백업본으로 저장한후 원본 로그의 내용을 비우는 방식으로 저장해야 합니다.
그래서 옵션을 copytruncate를 사용해야 합니다.
copytruncate
Truncate the original log file in place after creating a copy, instead of moving the old log file and optionally creating a new one, It can be used when some program can not be told to close its logfile and thus might continue writing (appending) to the previous log file forever. Note that there is a very small time slice between copying the file and truncating it, so some logging data might be lost. When this option is used, the create option will have no effect, as the old log file stays in place.
logrotate의 설정 옵션에 대하여 조금 더 알아보면은,
보다 더 많은 옵션과 설명을 보시려면, http://linuxcommand.org/man_pages/logrotate8.html를 참고하세요.
superuser 사이트입니다. 옵션에 대해서 한글로 자세히 설명되어 있습니다.
http://www.superuser.co.kr/linux/logrotate/page04.htm