
Cloudera CDH/CDP 및 Hadoop EcoSystem, Semantic IoT등의 개발/운영 기술을 정리합니다. gooper@gooper.com로 문의 주세요.
HADOOP 설치.
1대의 서버급 PC에 HADOOP 을 우선 여기저기 널려있는 문서를 찾아서 설치부터 하기로 했다.
RDB와의 유연한 연동 테스트를 위해서 스트레스 테스트를 위해서 설치부터 진행한다.
1. vmware OS 준비
CPU : 2
RAM : 2GB
HDD : 20GB
로 세팅하여 3대를 준비한다.
2. 기본 설치준비 사항. (2012.06.18일 기준 최신버전을 다 받았다)
OS 는 리눅스 (Cent OS 5.7로 선택)
apache-hadoop : 1.03
jdk : 1.7.0_05 ( 64bit )
3. 설치전 ( 이렇게 생겨먹은 형태로 설치하려고 한다. )
오라클 RAC를 설치할때와 마찬가지로 SSH 로 각 3대를 인증없이 로그인되도록 만들고나서
1:N 구조 형태로 연결을 한다.
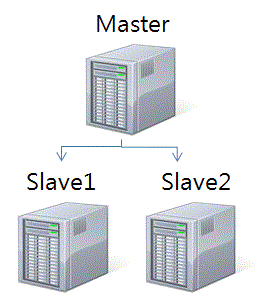
IP : 192.168.0.141 ( master )
IP : 192.168.0.142 ( slave1 )
IP : 192.168.0.143 ( slave2 )
master나 slave이름은 호스트이름으로 정하기로 한다. ( 남들도 그렇게 하드라고... )
설치 파일도 그렇고 메모리도 그렇고 기본설치할때는 생각보다 메모리를 적게 먹는다.
오라클처럼 GUI가 제공되는것은 아니지만 오픈소스만의 좀 있어보이는 설치방식(?) 도 마음에 든다
4. 기본 공통 설치 ( 각 OS 이미지에 공통으로 적용될것을 먼저 진행하여 복사를 한다.
ㄴ. hadoop 소스파일 풀어서 원하는곳에 넣기. ( /usr/local/hadoop )
ㄷ. 환경설정파일 수정.
- hosts 파일 수정
[hadoop@master conf]$ cat /etc/hosts
# Do not remove the following line, or various programs
# that require network functionality will fail.
127.0.0.1 localhost.localdomain localhost
192.168.0.141 master
192.168.0.142 slave1
192.168.0.143 slave2
- profile 또는 해당 사용자의 profile ( 나는 그냥 전체 적용시켜버리겠다 )
/etc/profile 에 아래 내용 추가
HADOOP_HOME=/usr/local/hadoop
JAVA_HOME=/usr/local/java/j2se
CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib/ext
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
export HADOOP_HOME_WARN_SUPPRESS=" " # 파티션 포멧할때 에러가 나서 사이트 검색해서 추가함.
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE INPUTRC JAVA_HOME CLASSPATH HADOOP_HOME
ㄹ. 디렉토리 생성
- 네임노드용 디렉토리와, 작업용, 데이터용 디렉토리를 생성한다. ( 원래는 네임노드는 name만 데이터노드는 data만 있으면 되는데 귀찮아서;;; 한군데 다 만들고 그냥 vm-image clone 함.
$>mkdir -p /home/hadoop/work/mapred/system
$>mkdir -p /home/hadoop/work/data
$>mkdir -p /home/hadoop/work/name
$>chmod 755 /home/hadoop/work/data
#위의 chmod 를 한것은?
네임노드가 올라오지 않고 에러가 자꾸 나서 찾아보고나서 권한수정
위 작업이 없이 그냥 하둡을 실행하면.
아래와 같은log4j에러가 찍힌다. 혹시 보게되면 이것을 꼭 해주길;;;
WARN org.apache.hadoop.hdfs.DFSClient: Error Recovery for block null bad datanode[0] nodes == null
WARN org.apache.hadoop.hdfs.DFSClient: Could not get block locations. Source file "/home/hadoop/work/mapred/system/jobtracker.info" - Aborting...
WARN org.apache.hadoop.mapred.JobTracker: Writing to file hdfs://192.168.0.141:9000/home/hadoop/work/mapred/system/jobtracker.info failed!
WARN org.apache.hadoop.mapred.JobTracker: FileSystem is not ready yet!
WARN org.apache.hadoop.mapred.JobTracker: Failed to initialize recovery manager.
org.apache.hadoop.ipc.RemoteException: java.io.IOException: File /home/hadoop/work/mapred/system/jobtracker.info could only be replicated to 0 nodes, instead of 1
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:1558)
at org.apache.hadoop.hdfs.server.namenode.NameNode.addBlock(NameNode.java:696)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:563)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1388)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1384)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1121)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:1382)
at org.apache.hadoop.ipc.Client.call(Client.java:1070)
at org.apache.hadoop.ipc.RPC$Invoker.invoke(RPC.java:225)
at $Proxy5.addBlock(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:82)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:59)
at $Proxy5.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient$DFSOutputStream.locateFollowingBlock(DFSClient.java:3510)
at org.apache.hadoop.hdfs.DFSClient$DFSOutputStream.nextBlockOutputStream(DFSClient.java:3373)
at org.apache.hadoop.hdfs.DFSClient$DFSOutputStream.access$2600(DFSClient.java:2589)
at org.apache.hadoop.hdfs.DFSClient$DFSOutputStream$DataStreamer.run(DFSClient.java:2829)
5. 각 os image 부팅후 각 서버별로 설정 (참고 : 지금 설치하는 사용자는 hadoop이라는 사용자로 설치한다. )
각서버를 패스워드 없이 드나들고 , hadoop 이 각 노드와의 처리를 위해서 노인증처리 작업을 한다.
- 아래 작업은 3대중에 1곳만 한다. (어차피 복사할거라..)
- hadoop 계정으로 로그인후 ( 로그인 되어있으면 말고.. )
$> cd [Enter] ( 홈디렉토리 이동 )
$> ssh-keygen -t rsa [Enter]
$> [Enter][Enter][Enter][Enter][Enter][Enter] ....
* 이렇게 하고나서 다시 프롬프트가 나오면 확인차
$> ls -al [Enter]
* .ssh 라는 이름의 숨겨진 디렉토리가 보일것이다.
$> cd .ssh [Enter]
$> cp id_rsa.pub authorized_keys [Enter]
* 이제 다른 서버로 접속 ( master에서 설치했다면 slave1 이나 slave2 로 접속한다.)
$> ssh slave1
[어쩌고 저쩌고] yes/no ? 물을것이다.
한번도 들어와 본적이 없는곳이라면 물어보겠지 일종의 암호를 저장하시겠습니까? 와 비슷한... (암호를 저장하는것은 아니다!)
- yes 하면 패스워드를 물을것이 들어가본다.
- 잘 들어가지면 다시 나온다.
$>exit [Enter]
해당 .ssh 디렉토리내부를 다른서버에 복사
* 위의 작업을 한곳을 제외한 나머지곳에는 ssh-keygen -t rsa 명령어 치고 엔터나치면서 .ssh 디렉토리를 생성하고나서.
$>scp * hadoop@slave1:.ssh [Enter]
* 그러면 패스워드 한번 묻고 복사가 될것이다.
* 그렇게 하고나서 다시 ssh master 나 ssh 아이피등 어찌되었든 3개의 서버를 와따갔다해보면
yes/no ? 최초에 한번묻고 패스워드는 안물어 볼 것이다.( 이래야 정상인데;;; )
ㄴ. Hadoop 관련 설정 ( 내 하둡 위치 : /usr/local/hadoop )
- conf 디렉토리 안에 설정파일 몇가지를 수정한다.
- hadoop-env.sh
#JAVA_HOME 수정후 주석풀기.
#HADOOP_HEAPSIZE 주석풀기.
#HADOOP_SSH_OPTS 주석풀기. [data노드가 연결이 안되어서 이것저것 찾아보다가 이부분도 풀었다;;]
- core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.0.141:9000</value>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/work/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/work/data</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
</configuration>
- mapred-site.xml
<configuration>
<property>
<name>mapred.map.child.java.opts</name>
<value>-Xmx200m </value>
</property>
<property>
<name>mapred.reduce.child.java.opts</name>
<value>-Xmx200m </value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://192.168.0.141:9001</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/home/hadoop/work/mapred/system</value>
</property>
</configuration>
- slaves
192.168.0.142
192.168.0.143
위 설정파일(4가지)도 각 서버에 전부 적용해도 된다. 여기다가 쓴이유는..... 아무생각없이 작성하다가;;; 여기다가 썼다;
6. hadoop 띄우기[완료]
위에서 path를 hadoop밑의bin디렉토디도 추가했다면
$> hadoop namenode -format [Enter]
사실 위의 명령어를 한번 딱치면 format 이 실패했다고 떠버렸다. 처음이라 그런가 하여 다시 시도하면 바로 성공;;;
12/06/19 12:29:40 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/192.168.0.141
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.0.3
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.0 -r 1335192; compiled by 'hortonfo' on Tue May 8 20:31:25 UTC 2012
************************************************************/
Re-format filesystem in /home/hadoop/work/name ? (Y or N) Y # 다시 시도한 흔적 ㅎㅎ;
12/06/19 12:29:42 INFO util.GSet: VM type = 64-bit
12/06/19 12:29:42 INFO util.GSet: 2% max memory = 17.77875 MB
12/06/19 12:29:42 INFO util.GSet: capacity = 2^21 = 2097152 entries
12/06/19 12:29:42 INFO util.GSet: recommended=2097152, actual=2097152
12/06/19 12:29:43 INFO namenode.FSNamesystem: fsOwner=hadoop
12/06/19 12:29:43 INFO namenode.FSNamesystem: supergroup=supergroup
12/06/19 12:29:43 INFO namenode.FSNamesystem: isPermissionEnabled=true
12/06/19 12:29:43 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
12/06/19 12:29:43 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
12/06/19 12:29:43 INFO namenode.NameNode: Caching file names occuring more than 10 times
12/06/19 12:29:43 INFO common.Storage: Image file of size 112 saved in 0 seconds.
12/06/19 12:29:43 INFO common.Storage: Storage directory /home/hadoop/work/name has been successfully formatted.
12/06/19 12:29:43 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.0.141
************************************************************/
ㄴ. 시작[완료]
$>start-all.sh [Enter]
starting namenode, logging to /usr/local/hadoop/libexec/../logs/hadoop-hadoop-namenode-master.out
192.168.0.142: starting datanode, logging to /usr/local/hadoop/libexec/../logs/hadoop-hadoop-datanode-slave1.out
192.168.0.143: starting datanode, logging to /usr/local/hadoop/libexec/../logs/hadoop-hadoop-datanode-slave2.out
192.168.0.141: starting secondarynamenode, logging to /usr/local/hadoop/libexec/../logs/hadoop-hadoop-secondarynamenode-master.out
starting jobtracker, logging to /usr/local/hadoop/libexec/../logs/hadoop-hadoop-jobtracker-master.out
192.168.0.142: starting tasktracker, logging to /usr/local/hadoop/libexec/../logs/hadoop-hadoop-tasktracker-slave1.out
192.168.0.143: starting tasktracker, logging to /usr/local/hadoop/libexec/../logs/hadoop-hadoop-tasktracker-slave2.out
위 메세지 마냥 각 연결된 노드를 전부 띄워주는것 같다 [선지식이 없는 상태에서 하다보니 추측만 할뿐]
* 실제로 start-all.sh 파일을 열어보면 두개의 실행을 해주는것을 확인했다. [아래는 start-all.sh 파일]
bin=`dirname "$0"`
bin=`cd "$bin"; pwd`
if [ -e "$bin/../libexec/hadoop-config.sh" ]; then
. "$bin"/../libexec/hadoop-config.sh
else
. "$bin/hadoop-config.sh"
fi
# start dfs daemons
"$bin"/start-dfs.sh --config $HADOOP_CONF_DIR
# start mapred daemons
"$bin"/start-mapred.sh --config $HADOOP_CONF_DIR
하나는 분산파일시스템 시작인것 같고. 하나는 맵리듀스인지 나발인지 올리는것 같다;;;;
ㄷ. 확인
이것도 관리자같은것이 있다[Oracle이나 MSSQL 같은 EM 은 아니고 그냥 상태 파악용??? 현황판?]
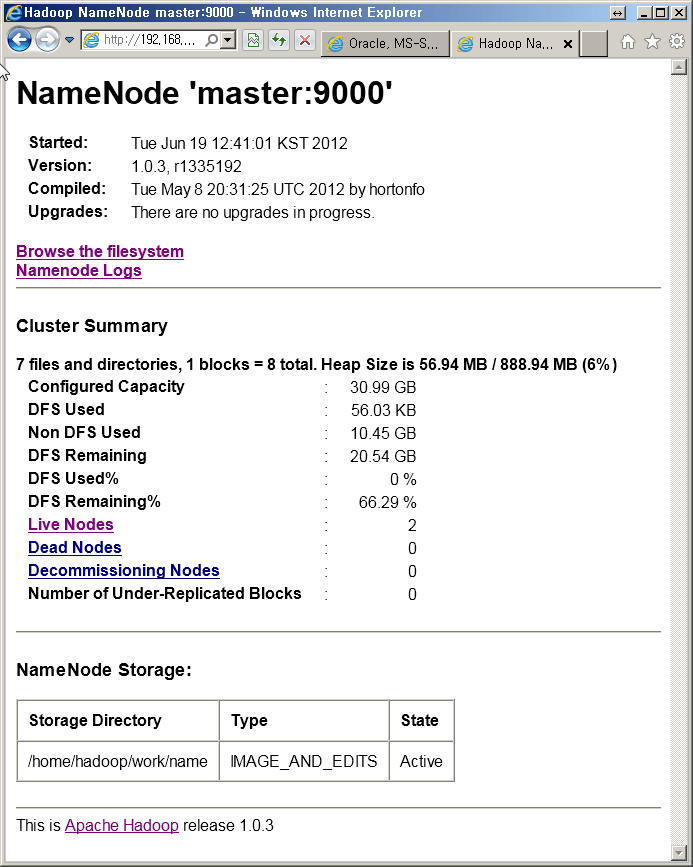
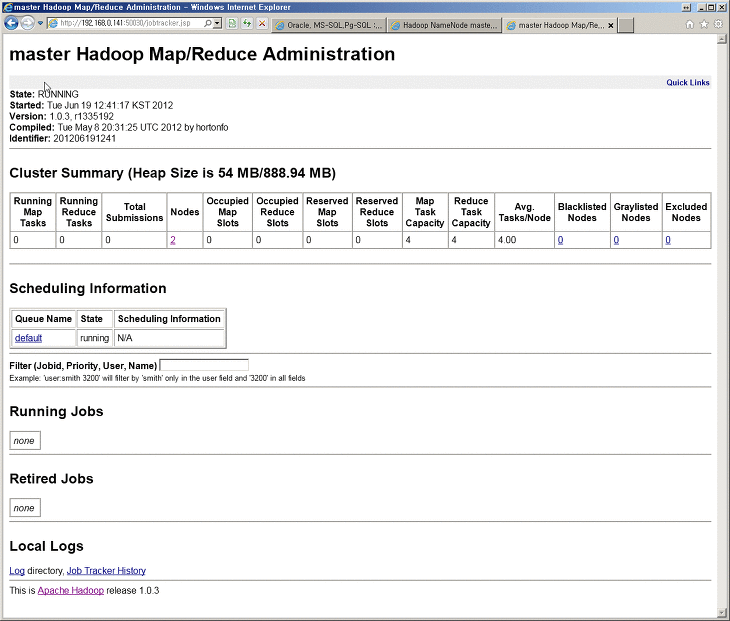
- 두개의 노드가 live하다라든가 [ 두개 노드 datanode만 말하는것 같다. ]
- 용량이 어쩌구 저쩌구 되어있고. [ heap 인걸보니 아마도 파일을 메모리에 올려놓고 사용하는 양을 예기하는것 같은데... ]
* 이제부터 책과 함께 이것저것 하면서 파봐야한다.
* 자바로 띄우는걸 보니 자바로 접근하는것이 상당히 유연할듯한데. 개인적으로 자바를 별로 안좋아라 해서 약간 걱정이다.
* 프로젝트있을때만 한 자바.... 개놈에 자바.... 아무튼 오라클과 hadoop 테스트 때문에 불가피하게 또 해야겠다.... (-.ㅜ)