
Cloudera CDH/CDP 및 Hadoop EcoSystem, Semantic IoT등의 개발/운영 기술을 정리합니다. gooper@gooper.com로 문의 주세요.
이클립스에서 생성한 jar 파일 hadoop 으로 실행하기
이클립스로 (maven) 생성한 jar 파일을 hadoop 으로 실행해보자
hadoop 설치 및 프로젝트 jar 생성은 이전 포스팅을 참고하시길
메이븐 (maven) 설치 및 이클립스 연동하기 쉬운설명
그럼 바로 시작 고고~
| jar파일 실행 준비 |
'ExWordCount.jar' 파일을 하둡으로 실행해 보도록 하겠다.
먼저 실행을 위한 준비작업을 해야한다.
알FTP 를 이용하여(등 다른방법 알아서^^;) ExWordCount.jar 파일을 하둡이 설치된 리눅스 단으로 복사한다.
이동 방법은 굳이 설명하지 않겠다.
필요하신분은 받으시라고 올려둔다.
직접 만들어서 실행해 보는데 의미가 있긴하지만..
 ExWordCount.jar
ExWordCount.jar패키지명 : kr.bigmark.wordcount
프로젝트명 : WordCount
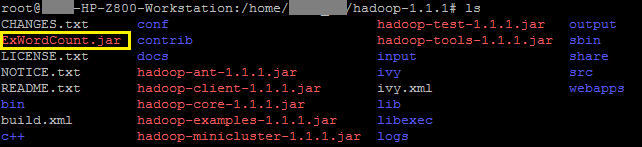
PuTTY 를 이용하여 하둡폴더가 설치된 곳으로 이동하여 ExWordCount.jar 파일이 잘있는지 확인한다.(안녕?)
위 그림에 'ExWordCount.jar 파일이 직접 생성한 jar 파일이다.
ExWordCount 를 실행하기 전에
wordcount 에 필요한 파일들을 먼저 만들어 보겠다.
# vi test01 test hadoop hadoop mywork goodjob # vi test02 hadoop easy hadoop puhaha test |
이렇게 두개의 파일을 만들고
input 폴더를 생성하여 안에 test01, test02 를 넣어준다.
# mkdir input/ # mv test01 input/ # mv test02 input/ |
# ls input/
입력하여 'input' 폴더안에 test01, test02 파일이 정상적으로 들어있는지 확인하자
![]()
| jar 파일 실행 및 결과확인 |
준비가 모두 완료되었으면 실행을 해보자
# hadoop jar ExWordCount.jar kr.bigmark.wordcount.WordCount input/ output/ |
(hadoop jar jar파일명 패키지명.프로젝트명 입력폴더 출력폴더) 순으로 입력한다.
![]()
실행이 완료되면 출력폴더인 'output' 폴더에 _SUCCESS, part-00000 파일이 생성되어 있을 것이다.
그럼 결과를 확인해보자.
# cat output/* |

결과를 보면 input 폴더에 있는 파일들의 wordcount (단어갯수) 를 파악하여 출력하는 것을 확인할 수 있다.