
Bigdata, Hadoop ecosystem, Semantic IoT등의 프로젝트를 진행중에 습득한 내용을 정리하는 곳입니다.
필요한 분을 위해서 공개하고 있습니다.
문의사항은 gooper@gooper.com로 메일을
보내주세요.
이번에 하둡 프로젝트를 하게 되면서 이클립스 메이븐 (maven) 을 사용하게 되었다.
메이븐 설치 방법은 어렵지 않으나
한 사이트에 깔끔하게 정리된곳을 찾기 힘들어 포스팅 해본다.
그전에 하둡 설치가 안되어있다면..
메이븐 다운로드 및 설치하기 |
메이븐은 다음 사이트에서 다운로드 받을 수 있다.
http://maven.apache.org/download.html

다운로드 페이지에서 Maven 3.0.4 (Binary zip) - apache-maven-3.0.4-bin.zip 을 다운 받는다. (현재 최신버전)
다운받은 zip 파일을 원하는 경로로 이동하여 압축해제 한다.
| 환경변수 등록 및 확인 |
다음으로 maven을 환경변수에 등록하여야 한다.
컴퓨터 - 속성 - 고급시스템설정 - 고급탭 - 환경변수 를 클릭하여 환경변수 창으로 이동한다.
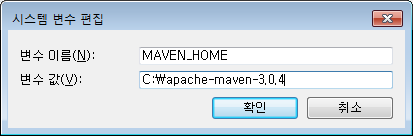
시스템 변수 - 새로만들기 를 클릭하여
위 그림과 같이 변수 이름과 변수 값을 입력한다.
변수 이름 : MAVEN_HOME
변수 값 : C:apache-maven-3.0.4 (압축해제한 경로)
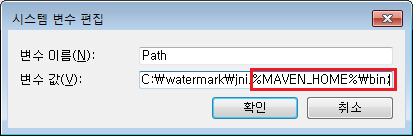
시스템 변수 Path를 선택하여 메이븐 경로를 다음과 같이 등록한다.
%MAVEN_HOME%bin;
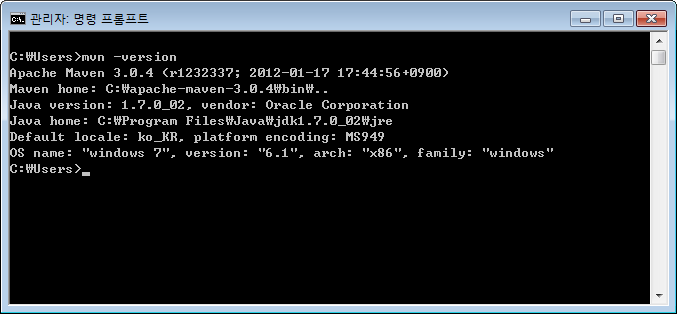
환경변수 등록이 완료 되었으면 커맨드창(cmd) 에서 'mvn -version'을 입력하여 메이븐이 정상적으로 실행되는지 확인한다.
이클립스 m2eclipse 플러그인 설치 및 연동 |
이클립스를 실행하여 상단메뉴의
'Help - Install New Software..' 를 클릭한다.
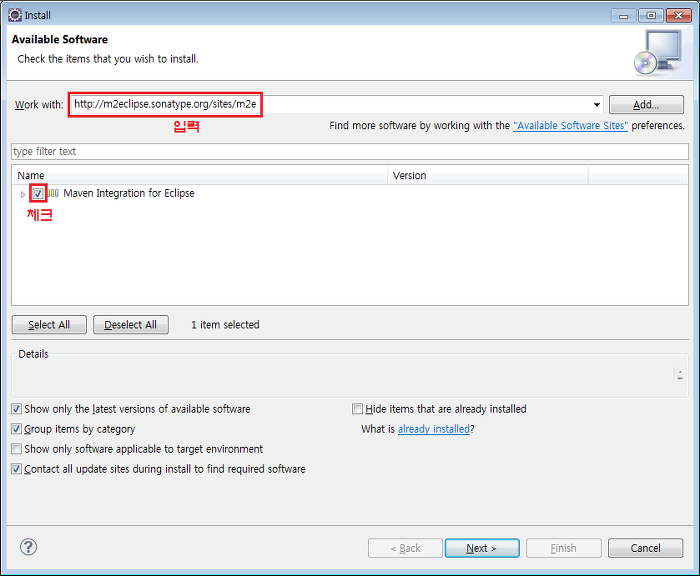
Work With 란에 http://m2eclipse.sonatype.org/sites/m2e 입력하여
검색된 Maven Intergration for Eclipse 를 선택하여 설치한다.
설치가 완료되면 이클립스가 재부팅 된다.
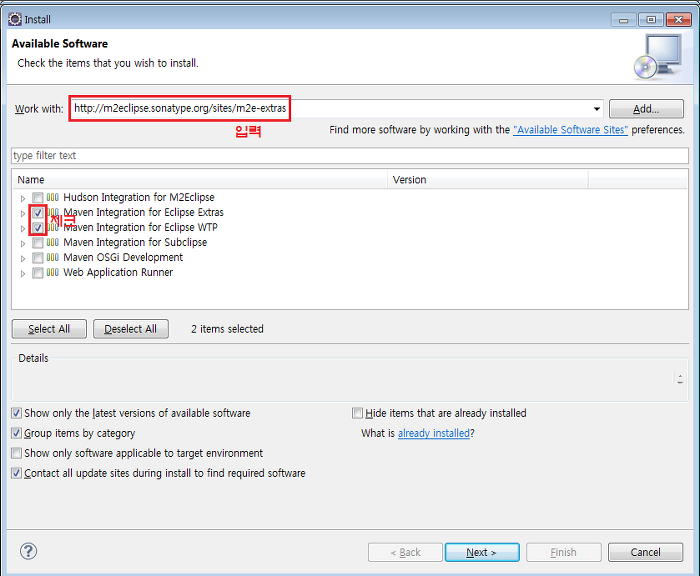
다시한번 'Help - Install New Software..' 를 클릭한다.
Work With 란에 http://m2eclipse.sonatype.org/sites/m2e-extras 입력하여
검색된 인스톨 항목중 'Maven Integration for Eclipse Extras'와 'Maven Integration for Eclipse WTP' 를 체크하여 설치한다.
설치가 완료되면 이클립스가 재부팅된다.
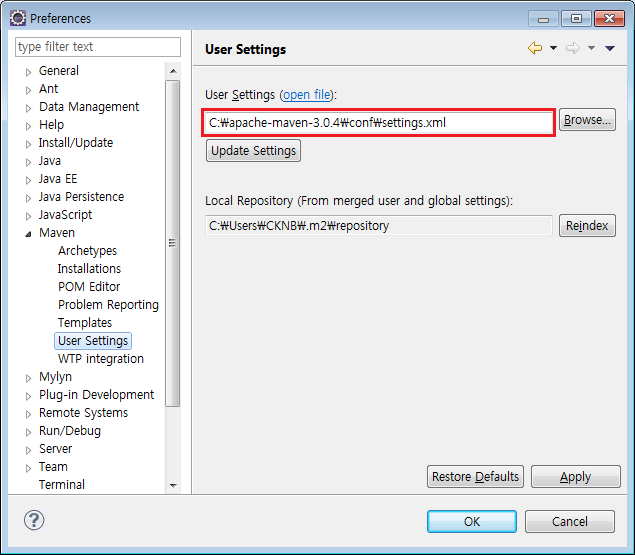
이클립스 상단메뉴의 'window - preference' 를 클릭한다.
'User Settings - Browse..' 버튼을 클릭하여
메이븐 경로의 하단폴더인 confsettings.xml 을 지정하고 Apply - OK 버튼을 차례로 눌려 적용한다.
이상으로 메이븐 설치 및 연동이 완료되었다.
| 이클립스 실행 시 경고창이 나올경우 |
이클립스 실행시 아래과 같은 경고창이 나올경우
| Maven Integration for Eclipse JDK Warning The Maven Integration requires that Eclipse be running in a JDK, because a number of Maven core plugins are using jars from the JDK. Please make sure the -vm option in eclipse.ini is pointing to a JDK and verify that Installed JREs are also using JDK installs. |
eclipse.ini에서 -vm옵션으로 JDK를 설정해주어야 한다.
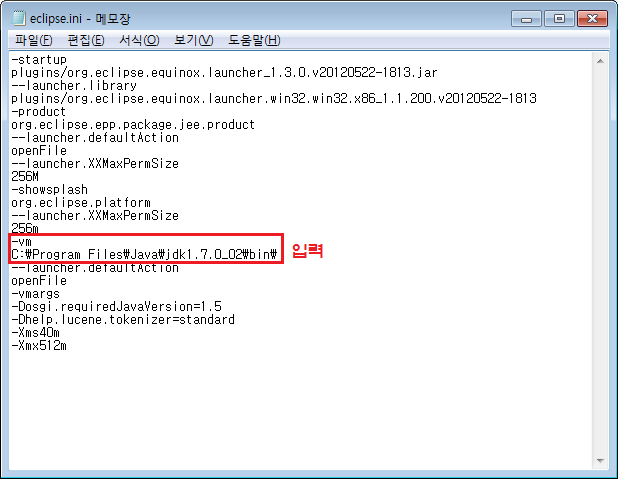
이클립스 폴더내의 eclipse.ini 파일을 열고
위 그림처럼 다음 설정을 추가한다.
| -vm C:Program FilesJavajdk1.7.0_02bin |
java가 설치된 곳의 jdkbin 경로로 설정하면된다.