
Cloudera CDH/CDP 및 Hadoop EcoSystem, Semantic IoT등의 개발/운영 기술을 정리합니다. gooper@gooper.com로 문의 주세요.
* 출처 : http://kysepark.blogspot.kr/2016/08/flume-kafka-100.html
Flume과 kafka를 사용하여 초당 100만개의 로그를 수집을 목표로 실행해보았다.
결론부터 얘기하자면 반은 성공, 반은 실패라고 할 수 있다.
실제 100만개의 로그를 kafka에 넣은 적도 있지만 지속 시간이 1분에서 2분 정도였다.(두 번 정도 100만 건을 넘은 적이 있다)
90만 건 이상의 로그를 넣었을 때에도 지속시간이 오래되지 않았다. (실제로는 다른 설정으로 테스트를 더 하느라 오래 돌려보지 못했다)
TCP congestion control에 의해 트래픽이 조정되면서 어느 정도 트래픽이 과부하다라고 판단되면 트래픽을 줄이는 것으로 보인다.
테스트 시, 이 과부하라는 판단을 시스템에서 어떻게 하는 지를 알 수가 없기 때문에 어느 때에는 80만~90만 건 이상까지도 처리하다가 어느 때에는 60만 건 이상도 처리되지 않는 일도 발생하였다.
다만, 테스트 방식이 몇 개 서버에서 로그 데이터를 한꺼번에 쏘게 되어 있다. 그러므로 이러한 방식으로 테스트를 할 때에 TCP congestion control에서 자꾸 혼잡이 일어난다고 판단하어 트래픽을 줄인 것으로 생각된다.(테스트를 할 때, 이 부분 때문에 혼란스러웠었다)
따라서 초당 100만개의 로그 데이터를 수집하는 게 가능해 보이긴 하지만 테스트 방식과 트래픽을 조정하는 TCP congestion control에 의해 지속적으로 100만 건을 kafka에 수집하는 데에는 실패하였다.
테스트에서 트래픽이 congestion control에 의해 조정되지 않고 안정적으로 처리 가능했던 로그 수는 초당 40만~50만 건이었다. 60만 건 이상을 한 꺼번에 쏘았을 때에는 트래픽이 줄어드는 현상을 보였었다.
하지만 70만 건 정도의 로그를 잘 처리하고 있을 때에는 지속적으로 안정된 모습을 보이기도 하였다. (테스트 시, 서버에서 수신되는 데이터를 점진적으로 증가시켜주는 방식으로 하면 70만~90만 건까지 처리가 가능했었다. 그러므로 80만 건 까지는 지속적으로 안정되게 처리할 수 있을 거라고 생각된다)


테스트 결과에 대한 내용은 이와 같다. 그럼 테스트를 어떻게 진행하였고 설정을 어떻게 했는 지에 대해 알아보자.
테스트 환경
테스트에 사용된 서버 및 네트워크 환경에 대해 간단하게 얘기하자면 다음과 같다.
CPU: 32 core
Memory: 256G
Network: 10G
위와 같은 환경의 서버 3대를 kafka cluster node와 flume agent를 실행하는데 사용되었다.
Syslog를 전송하는 서버도 위와 같은 환경의 서버로 3~4대를 사용하였다.
테스트 방법
시스템이나 flume의 설정을 바꾸면 해당 설정에 영향을 받는 인스턴스를 재시작한 후에 테스트를 하는 방법으로 하였다.
로그 데이터를 Syslog로 보내는 방식을 사용하였다.
Syslog UDP로 처음에 테스트를 시작하였으나 아무리해도 초당 3~4만 건을 넘길 수가 없었다.
주된 테스트는 Syslog TCP를 사용하여 이뤄졌다.
Cloudera 블로그에 나온 내용을 바탕으로 flume 설정이 이뤄졌다. 해당 내용은 아래 url에서 확인할 수 있다.
사실 이 테스트를 시작하게 된 계기도 위 블로그 내용을 본 후에 실제 가능한 지를 확인해보고자 함이었다.
테스트한 내용은 아래 그림과 같은 flume과 kafka 구성 하에 대량의 테이터를 얼마만큼 넣을 수 있는 지에 대해서 테스트하였다.
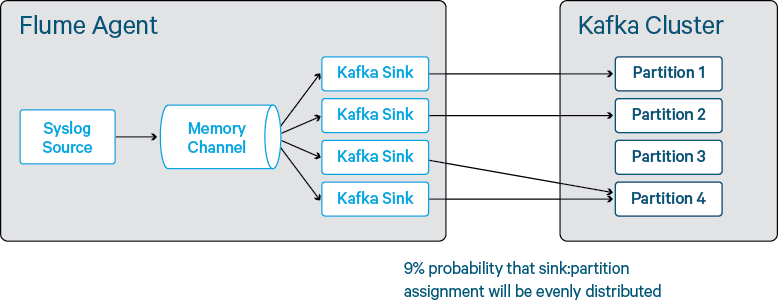
실시간으로 데이터가 얼마나 들어오는 지를 확인해야 해당 설정이 성능에 좋은 지 나쁜 지를 판단할 수 있었다.
따라서 iftop을 사용하여 실시간으로 얼만큼의 데이터를 처리하고 있는 지를 확인해가면서 테스트하였다.
테스트 로그 데이터
로그 : apache log
건당 데이터 크기: 120 byte
시스템 튜닝
Kafka cluster에서 초당 100만 건을 전송해서 처리해야 하므로 해당 시스템의 튜닝이 필요하다.
테스트를 하면서 이것저것 많이 수정해봤지만 실제 영향을 받는 설정은 아래 표와 같다.
아래 표의 설정 값은 실제 테스트에서 사용한 값이다.
항목 | 값 | 설명 |
|---|---|---|
| net.core.rmem_default | 104857600 | default receive buffer size |
| net.core.rmem_max | 33554432 | max receive buffer size |
| net.core.wmem_default | 104857600 | default send buffer size |
| net.core.wmem_max | 33554432 | max send buffer size |
| net.ipv4.tcp_rmem | 4096 8388608 33554432 | tcp receive buffer auto tuning. (값은 min, init, max 순이다) |
| net.ipv4.tcp_wmem | 4096 8388608 33554432 | tcp send buffer auto tuning. (값은 min, init, max 순이다) |
| net.ipv4.tcp_window_scaling | 1 | tcp window scaling. |
| net.ipv4.tcp_moderate_rcvbuf | 1 | tcp receive buffer auto tuning. |
| net.ipv4.tcp_sack | 1 | tcp selective ack |
| net.ipv4.tcp_max_syn_backlog | 30000 | max syn backlog |
위 설정 항목에 대한 자세한 내용은 다음 url에 있으니 참고하기 바란다.
위 설정 값이 절대적으로 맞다는 건 아니다. 테스트할 때에 위 설정 상태에서 어느 정도 테스트 성능을 이끌어냈다는 점이 있으므로 참고할 수는 있을 거라고 생각한다.
실제 튜닝할 때에는 sysctl 명령을 사용하여 수시로 변경하였다.
Flume 튜닝
Flume의 설정을 이리 저리 바꿔가면서 테스트한 결과 다음과 같은 설정을 사용했을 때의 성능이 뛰어났다.
기본적으로 flume에 포함되어 있는 KafkaSink로 kafka의 partition을 지정하려면 interceptor를 사용해야 한다.
그런데 어떤 식으로 설정해야 하는 지 정보가 없어 본래 소스에서 partition.key 프로퍼티로 partition을 간단하게 지정할 수 있게 수정한 KafkaSink를 사용하여 파티션을 지정할 수 있게 하였다.
또한 fd 개수가 모자라지 않게 ulimit를 2백만개로 설정하였다.
현재 설치한 kafka의 버전은 0.9 버전을 사용하여 클라우데라에서 만든 2.0.1-1.2.0.1.p0.5 버전이다.
하지만 CDH 5.7.1 버전에 포함된 flume에서는 kafka 0.8 버전을 베이스로 하고 있다. 따라서 아래의 설정에서 kafka producer 관련 설정은 kafka 0.8 버전의 설정을 따랐다.
# Name the components on this agent tier2.sources = r1 tier2.sinks = kk1 kk2 kk3 kk4 kk5 kk6 kk7 kk8 kk9 kk10 tier2.channels = c1 # Log Source tier2.sources.r1.channels = c1 tier2.sources.r1.type = multiport_syslogtcp tier2.sources.r1.ports = 7000 tier2.sources.r1.host = en2.igloosecurity.co.kr tier2.sources.r1.batchSize=8000 tier2.sources.r1.readBufferSize=16777216 # Use a channel which buffers events in memory tier2.channels.c1.type = memory tier2.channels.c1.capacity = 60000 tier2.channels.c1.transactionCapacity = 8000 # Sink tier2.sinks.kk1.channel = c1 tier2.sinks.kk1.type = com.igloosec.KafkaSink tier2.sinks.kk1.topic = ApacheLog tier2.sinks.kk1.brokerList = en2.igloosecurity.co.kr:9092 tier2.sinks.kk1.kafka.compression.codec = snappy tier2.sinks.kk1.kafka.request.required.acks=0 tier2.sinks.kk1.kafka.producer.type=async tier2.sinks.kk1.key=0 tier2.sinks.kk1.kafka.send.buffer.bytes=16777216 tier2.sinks.kk1.kafka.batch.num.messages=500 tier2.sinks.kk1.kafka.queue.buffering.max.ms=500 tier2.sinks.kk1.kafka.queue.buffering.max.message=50000 tier2.sinks.kk2.channel = c1 tier2.sinks.kk2.type = com.igloosec.KafkaSink tier2.sinks.kk2.topic = ApacheLog tier2.sinks.kk2.brokerList= en2.igloosecurity.co.kr:9092 tier2.sinks.kk2.kafka.compression.codec = snappy tier2.sinks.kk2.kafka.request.required.acks=0 tier2.sinks.kk2.kafka.producer.type=async tier2.sinks.kk2.key=1 tier2.sinks.kk2.kafka.send.buffer.bytes=16777216 tier2.sinks.kk2.kafka.batch.num.messages=500 tier2.sinks.kk2.kafka.queue.buffering.max.ms=500 tier2.sinks.kk2.kafka.queue.buffering.max.message=50000 ...... tier2.sinks.kk10.channel = c1 tier2.sinks.kk10.type = com.igloosec.KafkaSink tier2.sinks.kk10.topic = ApacheLog tier2.sinks.kk10.brokerList= en2.igloosecurity.co.kr:9092 tier2.sinks.kk10.kafka.compression.codec = snappy tier2.sinks.kk10.kafka.request.required.acks=0 tier2.sinks.kk10.kafka.producer.type=async tier2.sinks.kk10.key=9 tier2.sinks.kk10.kafka.send.buffer.bytes=16777216 tier2.sinks.kk10.kafka.batch.num.messages=500 tier2.sinks.kk10.kafka.queue.buffering.max.ms=500 tier2.sinks.kk10.kafka.queue.buffering.max.message=50000 |
|---|
Kafka 추가 설정
Cloudera manger의 kafka 설정에서 고급메뉴에 다음과 같은 설정으 추가하였다.
socket.send.buffer.bytes=33554432 socket.receive.buffer.bytes=33554432 replica.socket.receive.buffer.bytes=33554432 queued.max.requests=50000 num.network.threads=10 fetch.purgatory.purge.interval.requests=100 producer.purgatory.purge.interval.requests=100 |
|---|
위 설정들이 실제 성능 향상에 도움이 됐는 지는 확인되지 않았다.
한 가지, 영향을 주는 부분이 있다고 생각되는 부분은 있다.
위 설정이 없었을 때에 apache 로그를 70만에서 90만 건 정도를 kafka에 넣고 있으면 hbase sink의 성능이 떨어졌었다.
보통 Hbase sink가 초당 13만건 정도를 처리하고 있었는데 apache로그를 kafka에 열심히 집어 넣게 되면 4만, 2만건 정도로 뚝 떨어졌던 것이다.