
Bigdata, Hadoop ecosystem, Semantic IoT등의 프로젝트를 진행중에 습득한 내용을 정리하는 곳입니다.
필요한 분을 위해서 공개하고 있습니다.
문의사항은 gooper@gooper.com로 메일을
보내주세요.
* 출처 : http://kysepark.blogspot.kr/2016/03/how-to-build-complex-event-processing.html
본 글은 클라우데라 블로그의 글을 정리한 내용이다. 원문은 아래 링크를 따라가면 볼 수 있다.
대략적인 블로그 글의 내용은 CDH를 business execution engine과 결합하여 CEP(Complex Event Processing)로서 사용할 수 있다는 내용으로 이를 무엇을 사용해서 어떻게 구현했다는 내용이다.
- CEP에 대해서
- Event Processing이란?
- 데이터 스트림을 추적 및 분석하여 좀 더 나은 insight와 결정을 할 수 있도록 해주는 것을 의미
- CEP란?
- Event Processing의 일종으로 여러 소스로부터 얻어낸 데이터를 결합하여 여러 이벤트들간의 패턴 및 복잡한 관계를 찾아내는 것을 의미
- CEP는 여러 데이터 소스들로부터 기회와 위협을 확인하고 이를 실시간으로 경고를 할 수 있도록 해준다.
- 오늘날 CEP는 매우 다양한 분야에서 사용되고 있다.
- 금융: 거래 분석, 금융사기 탐지
- 항공: 운항 모니터링
- 의료: 클레임 프로세싱, 환자 모니터링
- 에너와 통신: 정전 탐지
- 빅데이터
- 기하급수적인 데이터의 증가로 빅데이터 처리 필요함.
- CDH를 사용하여 이를 해결할 수 있다.
- Event Processing이란?
- Architecture and Design
- CEP를 만들기 위해 CDH를 사용한 architecture는 다음과 같다.
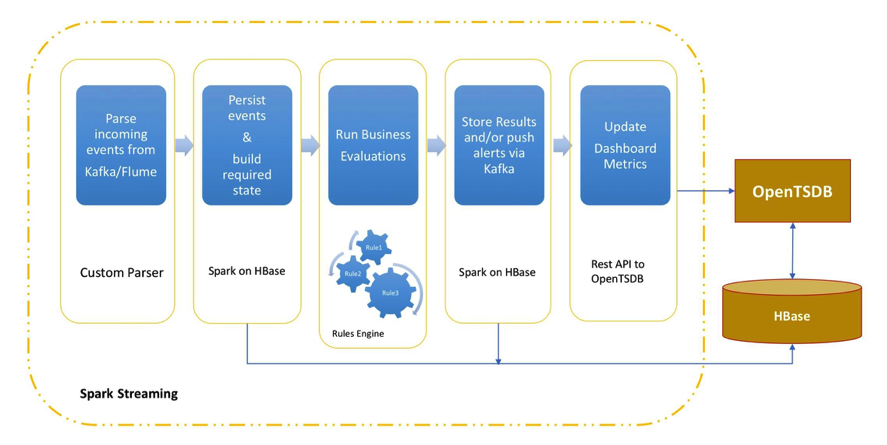
- 위 그림과 같은 architecture에서 사용된 컴포넌트들은 다음과 같다.
- Ingest: 이벤트 수집을 위해 Apache Kafka or Apache Flume 사용.
- Storage: 수집한 이벤트 저장에는 Apache HBase(또는 미래에는 아마 Kudu)를 사용.
- Alerting: Apache Kafka 또는 다른 직접적인 API를 통합하여 경고를 할 수 있게 함.
- Stream processing
- spark streaming을 사용하여 event processing을 처리함.
- Processing은 마이크로 배치로 처리되며 다음과 같은 일을 한다.
- Parsing
- Lookup
- Persistence
- Building of current state from a series of historical events
- Custom processing logic
- 일례로 다양한 sliding-window위의 여러 Spark RDD stream을 join하여 실시간에 가깝게 insight와 trend를 얻을 수 있다.
- 이 배치 작업은 매번 수초 간격으로 진행되며 수초보다 적은 end-to-end latency가 나게 한다.
- Business process management
- Rules framework는 technical 또는 non-technical한 사용자들도 복잡한 business logic을 디자인할 수 있게 해준다.
- 이 글에서는 Apahce spark와 Drools를 함께 사용하여 business의 요구사항에 대해 평가해본다.
- Metrics: OpenTSDB와 같은 time-series 데이터베이스의 대쉬보드를 통해 metrics를 제공한다. 또한 Cloudera Search + HUE를 사용해 같은 기능을 사용할 수 있다.
- 예제로 sepsis-shock criteria(패혈증 쇼크 기준)을 Drools를 사용하여 동작시켜보자. 해당 조건들은 이곳에 언급된 내용들을 다룬다.

- 위 그림에서 볼 수 있듯이 24시간내에 환자의 두 개의 vital이 범위를 넘어갈 경우 SIRS 기준에 부합하게 된다.
- 이 vital들은 다른 시각에 기준에 도달하게 된다. 따라서 매시간 환자의 상태를 재구성하기 위해 HBase를 사용하여 매시간 vital을 읽고 rules를 적용할 수 있게 한다.
- 예제를 위해 모든 event마다 모든 환자들의 vital을 가져온다고 가정하자. 그리고 snapshot/state-building step은 스킵한다.
- 환자가 SIRS 기준에 부합하게 되면 즉시 sepsis, severe sepsis, septic shock등을 순서대로 체크해야한다. 이 평가 프로세스의 flow chart는 다음과 같다.
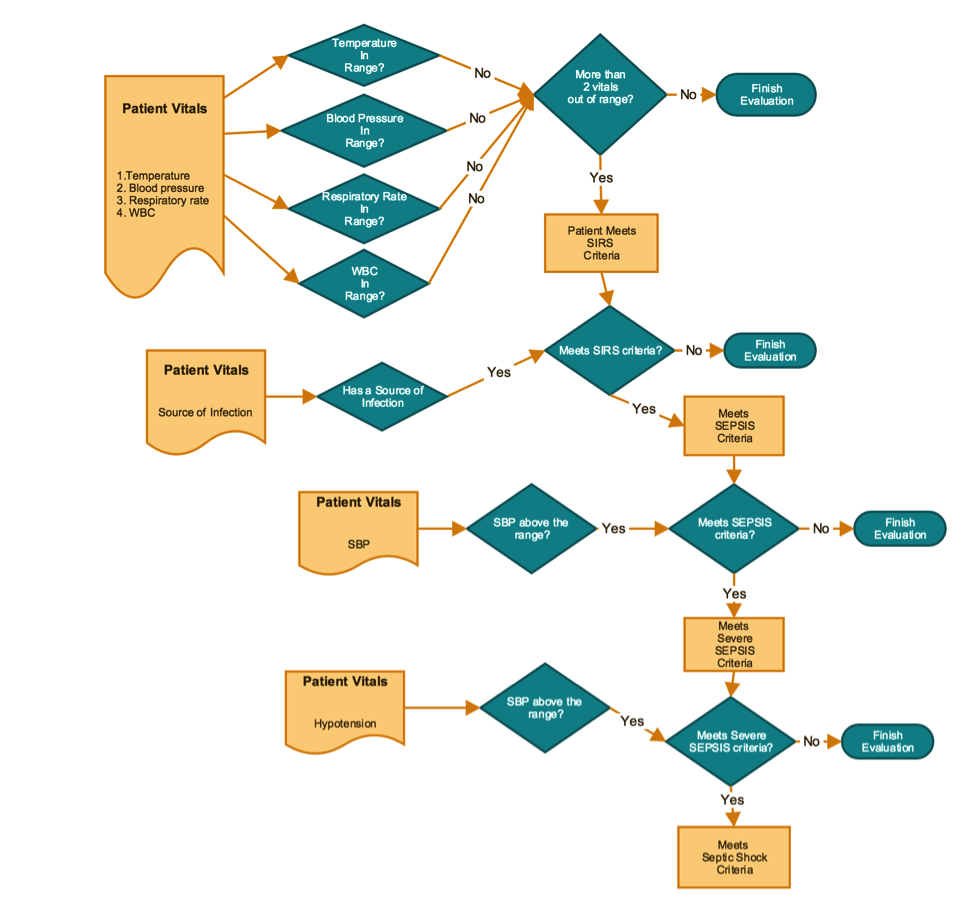
- 모든 조건들을 찾아내고 업무자들에게 친숙하게 데모를 만들기 위해 Drools decision tables를 사용한다. 이러한 접근은 business logic을 Java/Scala code 또는 custom syntax로 가지는 것보다 좀 더 많은 관중(business analyst 포함)들에게 가시성을 제공한다.
- 다음은 sepsis calculator를 충족시키기 위해 만들어진 decision table이다.
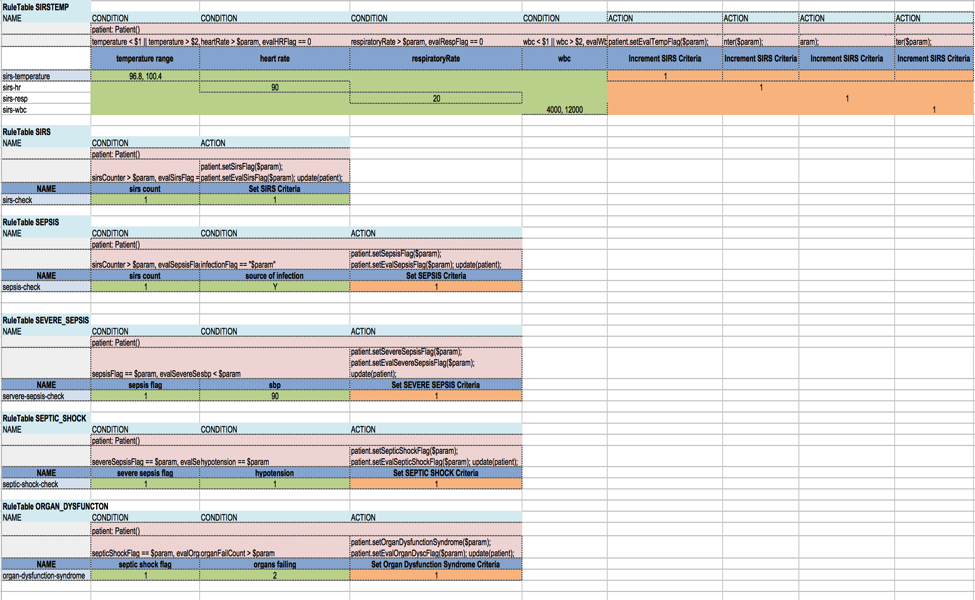
- 위 그림에 대하여
- 연한 빨강색으로 채워진 모든 셀들은 code로 돌아가도록 링크되어 있다.
- 오렌지색으로 채워진 모든 셀들은 rule이 성공적으로 평가된 이후에 정해진 값을 가진다.
- 녹색으로 채워진 모든 셀들은 주어진 rule을 만족시키기 위해 들어오는 데이터들의 범위들과 값들을 가진다.
- 모든 파란색으로 채워진 모든 셀들은 rule들의 이름과 그 조건들이다.
- 다음은 Spark와 Drools의 통합의 몇 가지 목표들이다.
- Rule들의 실행을 Spark/Streaming으로부터 seamless하게 만든다.
- 단순성을 위해 rule 엔진의 stateless 부분을 사용하라. 일정한 시간 간격을 유지하며 상태를 저장하는 spark의 sliding window를 사용할 수 있다.
- Rule을 요구사항에 기반하여 순차적 또는 무작위로 실행하라.
- 몇몇 metrics를 계산하기 위해 rule 실행 결과를 spark dataframe에 넣어라.
- CEP를 만들기 위해 CDH를 사용한 architecture는 다음과 같다.
- Coding
- 지금부터 위 목표를 달성하기 위한 절차와 코드 스니펫을 보여주겠다. 모든 코드는 https://github.com/mganta/sprue 에서 다운로드 받을 수 있다.
- 각 파티션에 session factory를 한번만 초기화한다. 그리고 모든 다음 dstream 실행에서 재사용한다.KieContainer kContainer = kieServices.newKieContainer(kieRepository.getDefaultReleaseId());kContainer.newStatelessKieSession();
- 들어오는 데이터를 HBase에 저장한다.//store incoming data in hbasehbaseContext.streamBulkPut[Patient](patientStream, patientTable, HBaseUtil.insertIncomingDataIntoHBase, true)
- RDD의 각 이벤트마다 모든 rule들을 실행하고 평가 결과를 RDD와 함께 리턴한다.//evaluate all the rules for the batchpatientStream.foreachRDD(rdd => {val evaluatedPatients = rdd.mapPartitions(partitionOfRecords => {val ksession = KieSessionFactory.getKieSession(xlsFileName)val patients = partitionOfRecords.map(patient => {ksession.execute(patient)patient})patients})
- RDD를 dataframe으로 변환하고 몇몇 metrics을 계산한다.//convert to dataframeval patientdf = sqc.applySchema(evaluatedPatients, classOf[Patient])//compute statisticsval countMatrix = patientdf.groupBy("location").agg(max("evaluationDate"), sum("sirsFlag"), sum("sepsisFlag"), sum("severeSepsisFlag"), sum("septicShockFlag"), sum("organDysfunctionSyndrome"))countMatrix.show()
- HBase에 업데이트를 저장한다.
hbaseContext.streamBulkPut[Patient](patientStream, patientTable, HBaseUtil.insertEvaluatedDataIntoHBase, true - Time-series rest api를 호출하고 마이크로 배치 metrics를 게시한다. Time-series 대쉬보드는 이 데이터를 읽을 수 있다.(여기서 OpenTSDB를 어떻게 설치하는 지를 배울 수 있다.)
//opentsdb update statistics countMatrix.foreach(row => {TSDBUpdater.loadPatientStats(row.getString(0), row.getLong(1), row.getLong(2), row.getLong(3), row.getLong(4), row.getLong(5), row.getLong(6))}) - 위의 모든 절차들은 여기 spark driver code와 링크되어 있다.
- 이 예제는 무작위로 선출된 환자의 데이터 스트림 생성하기 위해 QueueStream을 사용한다. 실제 시나리오에서는 각 이벤트에서 hl7 메시지를 받게 된다.
- 예제를 실행하면 들어오는 각 이벤트에서 rule이 실해되는 걸 볼 수 있다. 그리고 각 상태의 그룹화된 metrics을 볼 수 있다. 이는 아래와 같다.
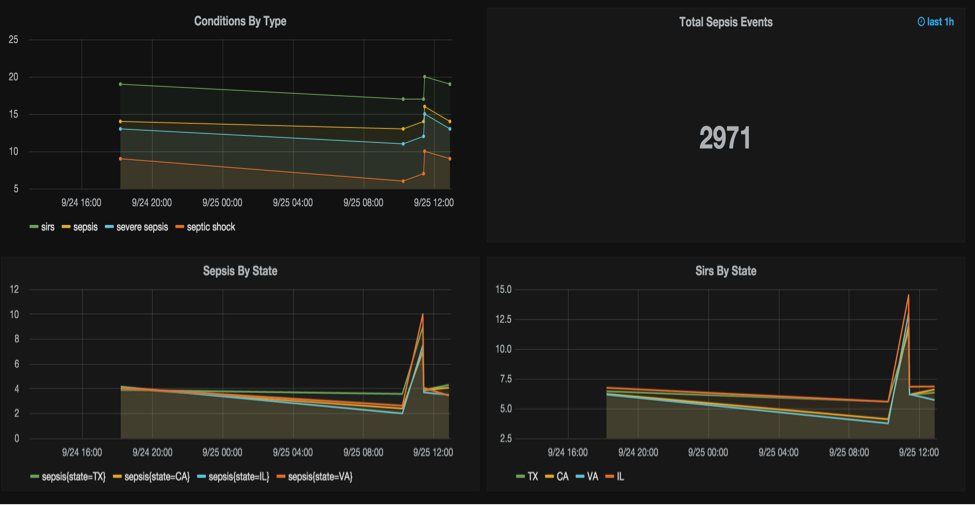
Total Patients in batch: 212 Patients with atleast one condition: 137+--------+-------------------+-------------+---------------+---------------------+--------------------+-----------------------------+|location|MAX(evaluationDate)|SUM(sirsFlag)|SUM(sepsisFlag)|SUM(severeSepsisFlag)|SUM(septicShockFlag)|SUM(organDysfunctionSyndrome)|+--------+-------------------+-------------+---------------+---------------------+--------------------+-----------------------------+| MS| 1443198199233| 3| 2| 2| 0| 0|| NE| 1443198199233| 8| 4| 4| 1| 0|| TX| 1443198199233| 10| 8| 8| 7| 1|| NM| 1443198199232| 8| 6| 6| 3| 0|| NY| 1443198199233| 6| 4| 3| 3| 0|| OK| 1443198199233| 7| 5| 3| 1| 0|| VA| 1443198199232| 16| 14| 12| 7| 1|| IL| 1443198199233| 5| 3| 3| 1| 0|| CA| 1443198199233| 7| 6| 6| 4| 0|| KS| 1443198199233| 12| 8| 8| 6| 0|| LA| 1443198199233| 14| 8| 7| 2| 1|| SC| 1443198199233| 12| 9| 6| 4| 0|| FL| 1443198199233| 7| 4| 4| 2| 0|| MN| 1443198199233| 8| 5| 5| 2| 0|| GA| 1443198199233| 14| 12| 12| 6| 0|+--------+-------------------+-------------+---------------+---------------------+--------------------+-----------------------------+Total Patients in batch: 247Patients with atleast one condition: 170+--------+-------------------+-------------+---------------+---------------------+--------------------+-----------------------------+|location|MAX(evaluationDate)|SUM(sirsFlag)|SUM(sepsisFlag)|SUM(severeSepsisFlag)|SUM(septicShockFlag)|SUM(organDysfunctionSyndrome)|+--------+-------------------+-------------+---------------+---------------------+--------------------+-----------------------------+| MS| 1443198199242| 1| 1| 1| 1| 0|| NE| 1443198199241| 14| 11| 11| 5| 1|| TX| 1443198199242| 13| 10| 9| 6| 0|| NM| 1443198199241| 11| 4| 3| 2| 0|| NY| 1443198199241| 13| 7| 6| 4| 0|| OK| 1443198199241| 7| 5| 5| 3| 0|| VA| 1443198199242| 10| 6| 6| 2| 0|| IL| 1443198199241| 17| 12| 12| 5| 1|| CA| 1443198199241| 17| 8| 7| 2| 0|| KS| 1443198199242| 12| 8| 7| 5| 2|| LA| 1443198199242| 15| 11| 9| 4| 2|| SC| 1443198199241| 13| 10| 9| 5| 0|| FL| 1443198199241| 10| 5| 5| 1| 0|| MN| 1443198199241| 10| 6| 6| 3| 0|| GA| 1443198199241| 7| 2| 1| 1| 0|+--------+-------------------+-------------+---------------+---------------------+--------------------+-----------------------------+ - 또는 OpenTSDB를 set up하면 다음과 같은 그림을 볼 수 있다.
- 각 파티션에 session factory를 한번만 초기화한다. 그리고 모든 다음 dstream 실행에서 재사용한다.
- 지금부터 위 목표를 달성하기 위한 절차와 코드 스니펫을 보여주겠다. 모든 코드는 https://github.com/mganta/sprue 에서 다운로드 받을 수 있다.
- 결론
- 복잡한 시스템을 설계할 때에는 rule 엔진을 사용하는게 유익한 선택이다.(Logic과 데이터의 분리는 domain expert에게 logic 결정에 대한 insight를 주면서 유연한 시스템을 낳는다.)
- 지금까지 본 바와 같이 CDH(for Spark, HBase, Kafka)를 rule엔진과 결합하여 사용하는게 복잡한 business logic을 평가하고 실시간으로 이를 동작시키는데 도움이 되는 걸 알 수 있다.